
La compréhension de la perception du chant peut émerger de deux types d'investigation. Le premier concerne les propriétés acoustiques du chant, qui sont systématiquement modifiées et examinées sur le plan perceptif. De telles recherches sont rares. Un autre type d'investigation compare les caractéristiques acoustiques de divers types de voix ou de phonations, comme les styles classique et ceinture ou la phonation pressée et normale. Comme ces classifications doivent être basées sur des indices auditifs perceptifs, ces recherches sont pertinentes sur le plan perceptif. De nombreuses recherches sur le chant possèdent ce type de pertinence perceptive.
La recherche sur la perception du chant n'est pas aussi développée que le domaine étroitement lié de la perception de la parole. Par conséquent, une présentation exhaustive ne peut être faite ici. Il s'agit plutôt de passer en revue un certain nombre de recherches différentes qui ne sont que partiellement liées les unes aux autres.
Lorsque nous écoutons un chanteur, nous pouvons noter un certain nombre de phénomènes perceptifs remarquables qui soulèvent un certain nombre de questions différentes. Par exemple : Comment se fait-il que nous puissions entendre la voix même lorsque l'orchestre est bruyant ? Comment se fait-il que nous identifions généralement correctement les voyelles du chanteur, même si la qualité des voyelles dans le chant diffère considérablement de celle à laquelle nous sommes habitués dans la parole ? Comment se fait-il que nous puissions identifier le sexe, le registre et le timbre de voix d'un chanteur lorsque la hauteur de la voyelle se situe dans une gamme commune à tous les chanteurs et à plusieurs registres ? Comment se fait-il que nous percevions le chant comme une séquence de hauteurs discrètes, même si les événements de fréquence fondamentale (F0) ne forment pas un modèle de fréquences fondamentales discrètes ? Ce sont là quelques-unes des principales questions qui sont abordées dans ce chapitre. Mais d'abord, un bref aperçu de l'acoustique de la voix chantée est présenté.
Fonctionnement de la voix
La théorie de la production vocale, illustrée schématiquement dans la figure 1, a été formulée par Fant (1960). Le système de production de la voix se compose de trois éléments de base : (1) le système respiratoire qui fournit une surpression d'air dans les poumons, (2) les plis vocaux qui découpent le flux d'air provenant des poumons en une séquence d'impulsions d'air quasi-périodiques, et (3) le conduit vocal qui donne à chaque son sa forme spectrale finale caractéristique et donc son identité timbrale. Ces trois composantes sont appelées respectivement (1) respiration, (2) phonation et (3) mise en forme du conduit vocal (articulation) et résonance. Le larynx fournit également une source sonore de chuchotement, et le conduit vocal assure également l'articulation des consonnes, mais ces composants ne sont pas abordés ici.
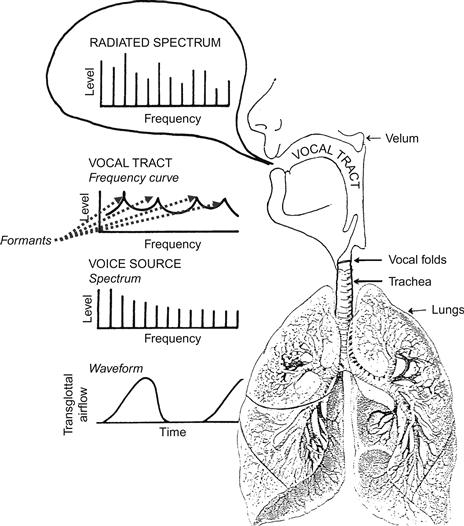
Figure 1 Illustration schématique de la fonction vocale. La source de la voix est le flux d'air transglottal pulsé, qui possède un spectre avec des partiels harmoniques, dont les amplitudes diminuent de façon monotone avec l'augmentation de la fréquence. Ce signal est injecté dans le conduit vocal, qui est un résonateur avec des résonances, appelées formants. Ils produisent des pics dans la courbe de fréquence du conduit vocal. Les partiels proches des formants sont renforcés et deviennent plus forts que d'autres partiels plus éloignés d'un formant.
Le flux d'air transglottal coupé est appelé la source vocale. C'est la matière première de tous les sons vocaux. Il peut être décrit comme un son complexe composé d'un certain nombre de partiels harmoniques. Cela implique que la fréquence de la nième partielle est égale à n fois la fréquence de la première partielle, qui est appelée la fréquence fondamentale (désormais F0) ou la première harmonique. La F0 est identique au nombre d'impulsions d'air se produisant en 1 seconde, ou en d'autres termes, à la fréquence de vibration des plis vocaux. Le F0 détermine la hauteur du son que nous percevons, en ce sens que la hauteur du son resterait essentiellement la même, même si le fondamental sonnait seul. Les amplitudes des partiels de la source vocale diminuent de façon monotone avec l'augmentation de la fréquence. Pour une intensité vocale moyenne, un partiel donné est plus fort de 12 dB qu'un partiel situé une octave plus haut ; pour une phonation plus douce, cette différence est plus importante. D'autre part, la pente du spectre de la source vocale ne dépend généralement pas du son vocal qui est produit.
Les différences spectrales entre les divers sons vocaux apparaissent lorsque le son de la source vocale est transféré dans le conduit vocal (c'est-à-dire des plis vocaux à l'ouverture des lèvres). La raison en est que la capacité du conduit vocal à transférer le son dépend fortement de la fréquence du son transféré. Cette capacité est maximale aux fréquences de résonance du conduit vocal. Les résonances du conduit vocal sont appelées formants. Les partiels de la source vocale qui sont les plus proches des fréquences de résonance sont émis par l'ouverture des lèvres avec une plus grande amplitude que les autres partiels. Par conséquent, les fréquences des formants se manifestent comme des pics dans le spectre du son rayonné.
La forme du conduit vocal détermine les fréquences des formants, qui peuvent varier dans des limites assez larges en réponse à des changements dans la position des articulateurs (c'est-à-dire les lèvres, le corps de la langue, la pointe de la langue, la mâchoire inférieure, le vélum, les parois du pharynx et le larynx). Ainsi, les deux fréquences de formants les plus basses, F1 et F2, peuvent être modifiées sur une plage de deux octaves ou plus, et elles déterminent l'identité de la plupart des voyelles, c'est-à-dire la qualité vocalique. Les fréquences formantes supérieures ne peuvent pas être modifiées autant et ne contribuent pas beaucoup à la qualité des voyelles. Elles signifient plutôt le timbre personnel de la voix.
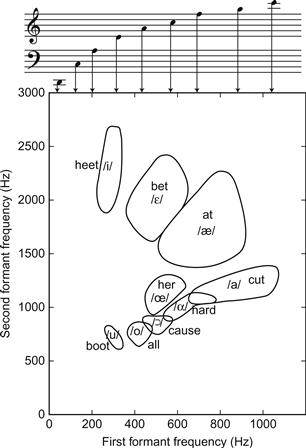
La qualité vocalique est souvent décrite dans un graphique montrant les fréquences de F1 et F2, comme dans la figure 2. Notez que chaque voyelle est représentée par une petite zone plutôt que par un point sur le graphique. En d'autres termes, on peut faire varier F1 et F2 dans certaines limites sans changer l'identité de la voyelle. Cela reflète le fait qu'une voyelle donnée possède normalement des fréquences de formants plus élevées chez les enfants et les femmes que chez les hommes. La raison de ces différences réside dans les différentes dimensions du conduit vocal, comme nous le verrons plus loin.
Phonation
La qualité de la voix peut être modifiée dans une large mesure grâce à des ajustements laryngés qui affectent la source de la voix. Dans la présente section, certains aspects de ces effets sont décrits.
A. Sonie, hauteur et type de phonation
On suppose généralement que l'intensité sonore de la voix correspond à l'intensité en décibels (dB) du niveau de pression acoustique (SPL). À proximité de la source sonore dans les salles réverbérantes, le SPL diminue avec l'augmentation de la distance ; le SPL est évidemment plus élevé à courte distance qu'à longue distance. Par conséquent, les valeurs SPL ne sont significatives que lorsqu'elles sont mesurées à une distance donnée. L'intensité sonore est souvent mesurée à une distance de 30 cm de l'ouverture des lèvres.
Le SPL a une relation assez complexe avec l'intensité sonore perçue. Le SPL d'une voyelle reflète principalement la force d'une seule partie, à savoir la partie la plus forte du spectre (Sundberg & Gramming, 1988 ; Titze, 1992). À l'exception des voyelles aiguës et des voyelles produites par une voix très douce, cette partie est une harmonique. Cette harmonique est normalement celle qui est la plus proche de F1, de sorte que les voyelles produites avec le même effort peuvent varier considérablement selon le F0 et la voyelle. Il est également courant qu'une variation du niveau de pression acoustique, comme cela se produit lorsqu'on fait varier le niveau d'écoute d'un enregistrement, ne soit pas perçue comme une variation de l'intensité sonore de la voix. Cette variation ressemble plutôt à une modification de la distance entre le microphone et la source.
Si le niveau d'écoute n'est pas étroitement corrélé à l'intensité sonore perçue de la voix, qu'est-ce qui détermine la perception de l'intensité sonore des voix ? Comme l'ont montré Ladefoged et McKinney (1963) et comme l'illustre la figure 3, l'intensité sonore moyenne des voyelles est plus étroitement liée à la pression sous-glottique sous-jacente qu'au NPS. La raison en est que nous faisons varier l'intensité sonore de la voix au moyen de la pression sous-glottique ; plus la pression est élevée, plus l'intensité sonore perçue de la voix est grande. La variation de la pression sous-glottique entraîne également des changements dans les caractéristiques de la source vocale autres que le NPS global. Dans la voix (comme dans la plupart des autres instruments de musique), les amplitudes des harmoniques supérieures augmentent plus rapidement que les amplitudes des harmoniques inférieures, lorsque l'intensité sonore de la voix augmente. Ce phénomène est illustré à la figure 4, qui montre le spectre moyen d'une voix produite par la lecture d'un texte à différents degrés d'intensité vocale. Ainsi, tant pour la parole que pour le chant, l'intensité vocale perçue augmente avec la dominance spectrale des harmoniques supérieures. Chez les chanteurs barytons, une augmentation de 10 dB de l'intensité globale entraîne une augmentation de 16 dB des partiels près de 3 kHz (Sjölander & Sundberg, 2004). Chez les chanteuses de formation classique, ce gain varie avec F0 (pour une revue de la littérature, voir Collyer, Davis, Thorpe, & Callaghan, 2009).
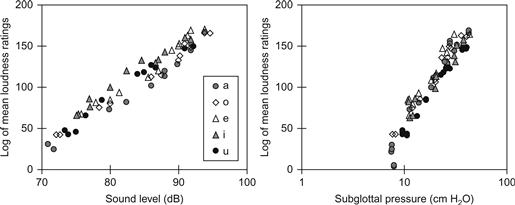
Figure 3 Niveau de pression acoustique (SPL) et évaluation moyenne de la sonie des voyelles indiquées produites à différents degrés de sonie vocale, représentés en fonction du SPL et de la pression sous-glottique (panneaux gauche et droit, respectivement).
Données de Ladefoged et McKinney (1963).
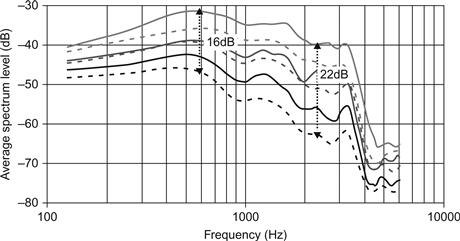
Figure 4 Spectres moyens à long terme d'une voix masculine non entraînée lisant le même texte à différents niveaux d'intensité vocale.
Données de Nordenberg et Sundberg (2004).
L'amplitude du fondamental de la source vocale est une autre caractéristique importante de la voix. Elle varie en fonction du mode de phonation qui, à son tour, est fortement influencé par l'adduction glottale (la force par laquelle les plis vocaux sont pressés l'un contre l'autre). Elle est souvent spécifiée en termes de différence de niveau entre les partiels 1 et 2 du spectre de la source, et désignée par H1-H2 (Harmonique 1-Harmonique 2). Lorsque l'adduction est faible (extrême : phonation respiratoire/hypofonctionnelle), la fondamentale est plus forte que lorsque l'adduction est ferme (extrême : phonation pressée/hyperfonctionnelle). D'un point de vue acoustique, H1-H2 est étroitement corrélé avec l'amplitude crête à crête des impulsions de flux d'air transglottal. Comme l'illustre la figure 5, les chanteurs barytons ayant reçu une formation classique ont un H1-H2 moyen pouvant atteindre près de 25 dB pour une phonation très douce (faible pression sous-glottique), alors que pour la phonation la plus forte, il n'est que de 7,5 dB (Sundberg, Andersson, & Hultqvist, 1999). Pour une pression sous-glottique relative donnée, la fondamentale des chanteurs de comédie musicale masculins a tendance à être plus faible, comme on peut le voir sur le même graphique (Björkner, 2008).
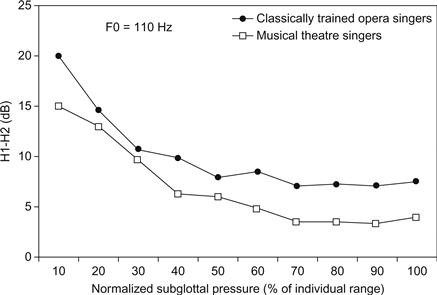
Figure 5 Valeurs moyennes de H1-H2 observées à la hauteur indiquée en fonction de la pression sous-glottique normalisée par rapport à la gamme de pression totale que les chanteurs ont utilisée pour cette hauteur.
Données de Björkner (2008).
Lorsque l'adduction glottique est réduite au minimum nécessaire pour produire un type de phonation non respiratoire, on obtient une "phonation fluide", dans laquelle le fondamental de la source vocale et les harmoniques supérieurs sont forts. Les non-chanteurs ont tendance à modifier les caractéristiques de la phonation en fonction de la hauteur et de l'intensité sonore, de sorte que les sons aigus et/ou forts sont produits avec une phonation plus pressée que les sons graves. Les chanteurs de formation classique, en revanche, semblent éviter ces changements "automatiques" de phonation.
Les amplitudes des impulsions d'écoulement d'air transglottales sont influencées par la zone glottale. Cela signifie qu'elles dépendent, entre autres, de la longueur du pli vocal ; pour une amplitude de vibration donnée, les plis vocaux plus longs ouvrent une plus grande surface glottique que les plis courts. Par conséquent, à une hauteur de son donnée et pour une pression sous-glottique donnée, un chanteur aux longs plis vocaux devrait produire des sons avec une plus grande amplitude crête à crête du flux d'air transglottique et donc une fondamentale de source vocale plus forte qu'un chanteur aux plis vocaux plus courts. Comme les voix graves ont des plis vocaux plus longs que les voix aiguës, on peut s'attendre à ce que l'amplitude du fondamental soit également incluse parmi les caractéristiques des différentes catégories de voix. Cela nous permet probablement de savoir si un individu phonise dans la partie supérieure, moyenne ou inférieure de sa gamme de fréquences. Une autre différence importante entre les classifications de voix concerne les fréquences des formants, comme nous le verrons plus loin.
En résumé, en dehors de la hauteur, il existe deux aspects principaux des voyelles qui peuvent être modifiés de manière assez indépendante : l'amplitude de la fondamentale, qui dépend fortement de l'adduction glottique, et l'amplitude des harmoniques, qui est contrôlée par la pression sous-glottique. Dans la voix des non-chanteurs, l'adduction glottique augmente généralement avec la hauteur et l'intensité vocale. Les chanteurs semblent éviter ces changements automatiques de la source vocale qui accompagnent les changements de hauteur ou d'intensité sonore. Ils ont besoin de varier le timbre de la voix pour des raisons expressives plutôt que physiologiques. On peut donc dire qu'ils orthogonalisent les dimensions phonatoires.
B. Registre
Le registre, également appelé mécanisme dans certains ouvrages, est un aspect de la phonation qui a fait l'objet de recherches considérables, mais cette terminologie est restée peu claire (voir par exemple Henrich, 2006). Il est généralement admis qu'un registre est une série de tons de gamme adjacents qui (a) sonnent de manière égale en termes de timbre et (b) sont ressentis comme étant produits de manière similaire. En outre, il est généralement admis que les différences de registre reflètent des différences dans le mode de vibration des plis vocaux. Un exemple frappant du concept de registre est le contraste entre les registres modal et falsetto de la voix masculine. La transition d'un registre à l'autre est caractéristique du fait qu'elle est souvent, mais pas nécessairement, associée à un saut de hauteur.
Dans la voix masculine, il existe au moins trois registres, le fry vocal, le modal et le falsetto. Ils couvrent les gammes les plus basses, les plus moyennes et les plus hautes de la voix. On suppose souvent que la voix féminine contient quatre registres : poitrine, médium, tête et sifflet. Ils couvrent respectivement la partie la plus basse, la partie moyenne inférieure, la partie moyenne supérieure et la partie supérieure de la gamme de sons. Le registre de friture vocale, parfois appelé registre de pulsation, apparaît souvent dans les fins de phrases du discours conversationnel. Les gammes de fréquences des registres se chevauchent, comme l'illustre la figure 6. Il convient également de mentionner que de nombreux spécialistes de la voix suggèrent qu'il n'existe que deux registres dans les voix masculines et féminines : lourd et léger, ou modal et falsetto.
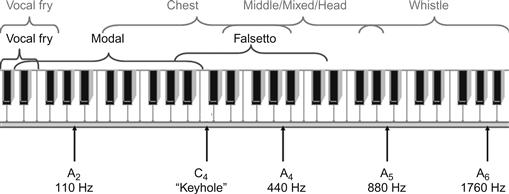
Figure 6 Plages approximatives des registres vocaux indiqués dans les voix féminines et masculines (rangées supérieure et inférieure).
Physiologiquement, les registres sont associés à des propriétés caractéristiques de la source vocale, c'est-à-dire qu'ils sont produits à partir de propriétés spécifiques de vibration des plis vocaux. Dans le fry vocal, les plis sont courts, laxes et épais. Les impulsions du flux transglottique se présentent souvent par groupes de deux ou plus, ou avec de longs intervalles de temps, de sorte que la période fondamentale est très longue, typiquement bien inférieure à 60 Hz. Dans le registre modal, les plis vocaux sont toujours courts et épais, mais les impulsions de flux arrivent une par une et la glotte est typiquement fermée pendant environ 20 à 50 % de la période en phonation forte. Dans le falsetto, les plis vocaux sont fins, tendus et longs, et la glotte ne se ferme généralement pas complètement pendant le cycle vibratoire.
Ces variations se traduisent par des caractéristiques acoustiques différentes qui sont perceptibles. Dans le fry vocal, la fondamentale est très faible, dans le modal elle est beaucoup plus forte, et dans le falsetto elle est souvent la partie la plus forte du spectre rayonné. Ceci est en grande partie une conséquence de la durée de la phase fermée combinée à l'amplitude de l'impulsion de débit.
Les chanteuses et les contre-ténors doivent le plus souvent utiliser à la fois leur registre modal/de poitrine inférieur et leur registre de fausset/de tête supérieur, et les transitions de registre doivent être aussi discrètes que possible. Ainsi, les différences timbrales entre ces registres doivent être réduites au minimum. Cet objectif semble être atteint par une fonction raffinée des muscles régulateurs de la hauteur du son, le cricothyroïde et le vocalis. Le muscle vocalis est situé dans le pli vocal, parallèlement à celui-ci, et lorsqu'il est contracté, il s'efforce de raccourcir et d'épaissir le pli. Le muscle cricothyroïdien a la fonction antagoniste, s'efforçant d'étirer et d'amincir les plis. Lorsque le muscle vocalis cesse brusquement de se contracter, la hauteur du son s'élève soudainement et le registre passe du modal au falsetto (comme dans le jodel), ce qui provoque un contraste timbral marqué. Une disparition plus graduelle de la contraction du vocalis avec la montée de la hauteur est probablement la technique utilisée pour obtenir la transition plus graduelle dont les chanteurs ont besoin. C'est d'ailleurs ce que suggère implicitement le fait que le terme "registre mixte" est souvent utilisé pour désigner le registre que les voix féminines utilisent dans la gamme de hauteur comprise entre E4 et E5 environ.
La fuite glottique, c'est-à-dire le flux à travers la glotte qui n'est pas modulé par les plis vocaux vibrants, est principalement associée à la phonation du falsetto chez les voix non entraînées. Les chanteurs, en revanche, semblent l'éviter ou le minimiser. Ainsi, on a constaté que les contre-ténors chantant dans leur registre de fausset et les femmes de formation classique chantant dans leur registre moyen/mixte phonaient parfois avec une fermeture complète de la glotte (Lindestad & Södersten, 1988).
Résonance
A. Fréquences formantiques à des hauteurs élevées
La plupart des chanteurs doivent chanter à des valeurs de F0 supérieures à celles utilisées dans la parole normale ; la F0 moyenne de la voix des adultes masculins et féminins est d'environ 110 Hz et 200 Hz, dépassant rarement environ 200 Hz et 400 Hz, respectivement. Ainsi, dans la parole, F1 est normalement plus élevé que F0. Dans le chant, les hauteurs de son les plus élevées pour le soprano, l'alto, le ténor, le baryton et la basse correspondent à des valeurs de F0 d'environ 1050 Hz (hauteur C6), 700 Hz (F5), 520 Hz (C5), 390 Hz (G4) et 350 Hz (F4), respectivement. Par conséquent, la valeur normale du F1 de nombreuses voyelles est souvent beaucoup plus basse que le F0 des chanteurs, comme on peut le voir sur la figure 2. Si le chanteur devait utiliser les mêmes fréquences d'articulation et de formants dans le chant que dans la parole, la situation illustrée dans la partie supérieure de la figure 7 se produirait. La fréquence fondamentale, c'est-à-dire la partie la plus basse du spectre, apparaîtrait à une fréquence bien supérieure à celle de la fréquence du premier formant (F1). En d'autres termes, la capacité du conduit vocal à transférer le son serait gaspillée à une fréquence où il n'y a pas de son à transférer.
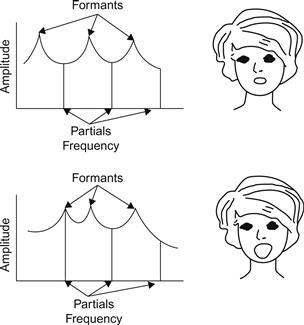
Figure 7 Illustration schématique de la stratégie des formants dans le chant aigu. Dans le cas supérieur, le chanteur a une petite ouverture de la mâchoire de sorte que F0 devient plus élevé que F1. Le résultat est une faible amplitude de la fondamentale. Dans le cas inférieur, l'ouverture de la mâchoire est élargie de sorte que F1 est élevé à une fréquence proche de F0. Le résultat est un gain considérable de l'amplitude du fondamental.
Reproduit de Sundberg (1977a).
Les chanteurs évitent cette situation. Leur stratégie consiste à abandonner les fréquences des formants de la parole normale et à rapprocher F1 de F0 (Garnier, Henrich, Smith, & Wolfe, 2010 ; Henrich, Smith, & Wolfe, 2011 ; Sundberg, 1975). Une méthode couramment utilisée pour atteindre cet effet semble être de réduire la constriction maximale du conduit vocal puis d'élargir l'ouverture de la mâchoire (Echternach et al., 2010 ; Sundberg, 2009). Ces deux modifications tendent à augmenter le F1 (cf. Lindblom & Sundberg, 1971). Ceci explique pourquoi les chanteuses, dans la partie supérieure de leur gamme de hauteurs, ont tendance à modifier l'ouverture de leur bouche d'une manière dépendante de la hauteur de la voix plutôt que d'une manière dépendante de la voyelle, comme dans la parole normale.
Le résultat acoustique de cette stratégie est illustré dans la partie inférieure de la figure 7. L'amplitude de la fondamentale, et donc le SPL global de la voyelle, augmente considérablement. Notez que ce gain de SPL résulte d'un phénomène résonatoire, obtenu sans augmentation de l'effort vocal.
La figure 8 montre les fréquences des formants mesurées chez une soprano chantant diverses voyelles à différentes hauteurs. Comme on peut le voir sur la figure, la chanteuse a maintenu les fréquences des formants de la parole normale jusqu'à la hauteur où F0 se rapproche de F1. Au-dessus de cette hauteur, F1 a été élevée à une fréquence proche de F0.
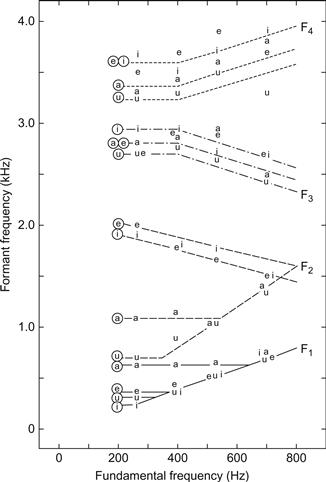
Figure 8 Fréquences formantes des voyelles indiquées (symboles de l'Alphabet phonétique international) mesurées chez une soprano professionnelle chantant différentes voyelles à différentes hauteurs. Les lignes montrent schématiquement comment elle a modifié les fréquences des formants avec la hauteur. Les valeurs représentées par les symboles encerclés ont été observées lorsque le sujet les soutenait en mode vocal.
D'après Sundberg (1975).
Quels chanteurs utilisent cette stratégie de formants en fonction de la hauteur ? Cette stratégie a été documentée chez les chanteurs sopranos (Johansson, Sundberg, & Wilbrand, 1985 ; Joliveau, Smith, & Wolfe, 2004 ; Sundberg, 1975) mais elle est également adoptée dans d'autres cas, lorsque le chanteur chante à un F0 supérieur à la valeur normale du F1 (Henrich et al., 2011). En consultant à nouveau la Figure 2, nous constatons que pour les voix de basse et de baryton, la plupart des voyelles ont un F1 supérieur à leur F0 supérieur. Pour les ténors et les altos, il en va de même pour certaines voyelles seulement, et pour les sopranos, pour peu de voyelles. Ainsi, on peut supposer que la stratégie des formants en fonction de la hauteur est appliquée par les chanteurs basse et baryton pour certaines voyelles dans le haut de leur gamme de hauteur, par les ténors pour certaines voyelles dans la partie supérieure de leur gamme de hauteur, par les altos pour de nombreuses voyelles dans la partie supérieure de leur gamme de hauteur, et par les sopranos pour la plupart des voyelles sur la majeure partie de leur gamme de hauteur. Une étude de l'ouverture des mâchoires de chanteurs professionnels de formation classique pour différentes voyelles chantées à différentes hauteurs a confirmé ces hypothèses pour les voyelles /α/1 et /a/, mais pour les voyelles antérieures telles que /i/ et /e/, la stratégie semble être d'abord d'élargir la constriction de la langue et ensuite d'élargir l'ouverture de la mâchoire (Sundberg & Skoog, 1997).
L'élargissement de l'ouverture de la mâchoire affecte en premier lieu le F1, mais les fréquences de formants plus élevées sont également affectées. Ceci est également illustré dans la figure 8 ; toutes les fréquences des formants changent lorsque F1 s'approche du voisinage de F0.
B. Le groupe de formants du chanteur
Bien que les chanteuses gagnent beaucoup en niveau sonore en accordant leur F1 au voisinage de F0, les chanteurs classiques masculins doivent utiliser une stratégie de résonance totalement différente. Le simple fait de chanter très fort ne les aiderait pas à faire entendre leur voix lorsqu'ils sont accompagnés par un orchestre puissant. La raison en est que la parole masculine présente une distribution moyenne de l'énergie sonore similaire à celle de nos orchestres symphoniques (voir figure 9). Par conséquent, un orchestre puissant masquerait très probablement la voix d'un chanteur masculin si elle avait les mêmes propriétés spectrales que dans la parole. Cependant, les ténors, les barytons et les basses produisent des spectres dans lesquels les partiels tombant dans la région de fréquence d'environ 2,5 à 3 kHz sont fortement renforcés, produisant un pic marqué dans l'enveloppe spectrale. La figure 10 compare des exemples typiques de la voyelle /u/ produite dans la parole et dans le chant par un chanteur professionnel. Ce pic a généralement été appelé le "formant du chanteur" ou le "formant du chant" (voir plus loin). Il a été observé dans la plupart des études acoustiques sur les ténors, les barytons et les basses (voir, par exemple, Bartholomew, 1934 ; Hollien, 1983 ; Rzhevkin, 1956 ; Seidner, Schutte, Wendler, & Rauhut, 1985 ; Sundberg, 1974 ; Winckel, 1953). On a constaté qu'il était en corrélation avec les évaluations d'une qualité perceptive appelée "résonance/anneau" (Ekholm, Papagiannis, & Chagnon, 1998). Comme nous l'expliquerons plus loin, elle rend la voix plus audible en présence d'un accompagnement orchestral fort.
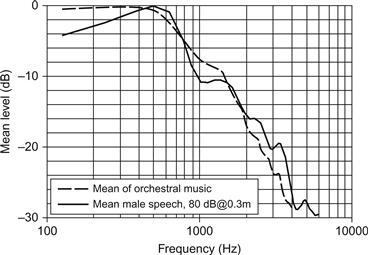
Figure 9 Spectres moyens à long terme montrant la distribution typique de l'énergie sonore dans les orchestres symphoniques occidentaux et dans la parole normale (courbes en pointillés et pleines).
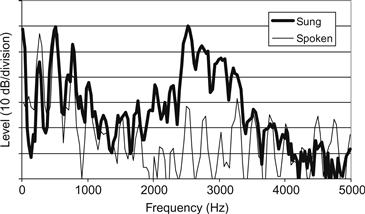
Figure 10 Spectres d'une voyelle /u/ parlée et chantée (courbes fines et lourdes). Le pic entre 2,5 et 3 kHz est appelé le groupe de formants du chanteur.
Lorsque les formants se rapprochent en fréquence, la capacité du conduit vocal à transférer le son augmente dans la région de fréquence correspondante. En fait, le pic spectral du formant du chanteur peut être expliqué comme la conséquence acoustique du regroupement des F3, F4 et F5 (Sundberg, 1974). C'est pourquoi il est appelé ci-après le cluster de formants du chanteur. Son amplitude dépend de la proximité de ces formants et, bien sûr, de la pression sous-glottique, c'est-à-dire de l'intensité sonore de la voix.
Les fréquences des formants sont déterminées par les dimensions du conduit vocal, c'est-à-dire par l'articulation, comme nous l'avons mentionné. Une configuration articulatoire qui regroupe F3, F4 et F5 de manière à générer le groupe de formants d'un chanteur implique un pharynx large (Sundberg, 1974). Un tel élargissement peut probablement être obtenu par un abaissement du larynx, et une position basse du larynx est typiquement observée chez les chanteurs masculins de formation classique (Shipp & Izdebski, 1975). Ainsi, le groupe de formants du chanteur peut être compris à la fois acoustiquement et articulatoirement.
La fréquence centrale du groupe de formants du chanteur varie légèrement entre les classifications vocales. Cela a été démontré en termes de spectres moyens à long terme (LTAS) par Dmitriev et Kiselev (1979). Pour les basses, la fréquence centrale était proche de 2,3 kHz, et pour les ténors, proche de 2,8 kHz. Ces résultats ont ensuite été corroborés par plusieurs chercheurs (Bloothooft & Plomp, 1988 ; Ekholm et al., 1998 ; Sundberg, 2001). La variation est faible, mais elle s'est avérée pertinente sur le plan perceptif lors d'un test d'écoute auquel ont participé des experts chargés de déterminer la classification de stimuli synthétisés (Berndtsson & Sundberg, 1995).
Il semble essentiel que l'intensité du groupe de formants du chanteur ne varie pas trop d'une voyelle à l'autre. Dans la parole neutre, le niveau de F3 peut typiquement différer de près de 30 dB entre un /i/ et un /u/ en raison de la grande différence de F2, ce qui entraîne une grande différence dans la proximité entre F2 et F3 dans ces voyelles (voir figure 2). Les chanteurs masculins de formation classique regroupent densément les F3, F4 et F5 dans le /u/, alors que leur F2 dans le /i/ est beaucoup plus faible que dans la parole. Par conséquent, le niveau du groupe de formants du chanteur en /i/ est beaucoup plus similaire à celui d'un /u/ dans le chant que dans la parole (Sundberg, 1990). On pourrait considérer le groupe de formants du chanteur comme une sorte de capuchon timbral uniforme pour les voyelles chantées qui devrait augmenter la similarité de la qualité vocale des voyelles. Cela aiderait les chanteurs à obtenir un effet legato dans les phrases contenant différentes voyelles.
Le groupe de formants d'un chanteur n'a pas été trouvé chez les sopranos (Seidner et al., 1985 ; Weiss, Brown, & Morris, 2001). Il peut y avoir plusieurs raisons à cela. L'une d'elles peut être purement perceptive. Le principe de base pour produire le groupe de formants d'un chanteur est que F3, F4 et F5 sont concentrés dans une gamme de fréquences plutôt étroite. Dans le chant aigu, la distance fréquentielle entre les partiels est évidemment grande (c'est-à-dire égale à F0). Une soprano qui regrouperait ces formants supérieurs produirait alors des voyelles avec le groupe de formants d'un chanteur uniquement sur les hauteurs où une partie se trouve dans la gamme de fréquences du groupe. Pour certaines tonalités, il n'y aurait pas de tel partiel, et ces tonalités sonneraient différemment de celles où il y avait un partiel frappant le cluster. Comme nous l'avons mentionné, les grandes différences de qualité vocale entre les tons adjacents d'une phrase ne semblent pas compatibles avec le chant legato.
Les chanteurs des genres de musique pop ne chantent pas avec le cluster de formants d'un chanteur. Au contraire, on a observé que certains d'entre eux produisent un pic spectral considérablement plus bas dans la plage de fréquences de 3,2 à 3,6 kHz (Cleveland, Sundberg, & Stone, 2001). Un tel pic a également été observé chez certains locuteurs professionnels, tels que les annonceurs radio et les acteurs, et dans ce que l'on a appelé les "bonnes" voix (Leino, Laukkanen, & Leino, 2011). Ce pic semble résulter d'un regroupement de F4 et F5, combiné à un spectre de source vocale qui produit des partiels harmoniques dans cette gamme de fréquences.
Le cluster de formants du chanteur est facilement reconnu par les experts de la voix. Cependant, de nombreux termes sont utilisés pour le désigner. Vennard, un éminent professeur de chant et chercheur sur la voix, l'appelle simplement "les 2800 Hz" qui produisent le "tintement" de la voix (Vennard, 1967). Il semble que le terme allemand "Stimmsitz", lorsqu'il est utilisé pour désigner les voix masculines de formation classique, soit associé au groupe de formants du chanteur qui est présent dans toutes les voyelles et à toutes les hauteurs (W. Seidner, communication personnelle, 2011).
C. Modification de la qualité des voyelles
Les déviations des fréquences de formants typiques de la parole normale qui sont produites par les chanteuses de formation classique à des hauteurs élevées sont assez importantes et impliquent une modification considérable de la qualité des voyelles. Cependant, la production du groupe de formants de la chanteuse est également associée à des modifications des qualités vocaliques typiques de la parole normale. La raison en est que l'élargissement nécessaire du pharynx et l'abaissement du larynx affectent également F1 et F2. Sundberg (1970) a mesuré les fréquences des formants des voyelles chantées par quatre chanteurs et a comparé ces fréquences avec les fréquences des formants rapportées par Fant (1973) pour les non-chanteurs. Comme le montre la figure 11, il existe des différences considérables entre les deux. Par exemple, F2 dans les voyelles avant telles que /i/ et /e/ n'atteint pas une fréquence aussi élevée dans le chant que dans la parole. Par conséquent, certaines voyelles dans le chant adoptent des fréquences de formants qui sont typiques d'une voyelle différente dans la parole. Par exemple, la F2 d'une /i/ chantée est presque la même que la F2 d'une /y/ parlée.
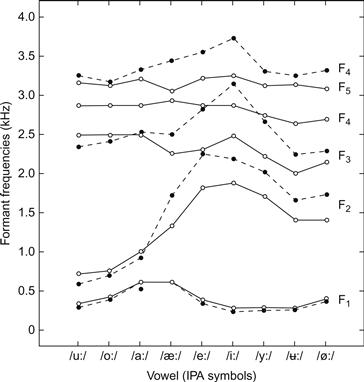
Figure 11 Fréquences moyennes des formants des voyelles indiquées, telles que produites par des non-chanteurs (courbes en pointillés, d'après Fant, 1973) et par quatre chanteurs basse/baryton (courbes pleines, d'après Sundberg, 1970). Notez que le F4 des non-chanteurs est légèrement supérieur au F5 des chanteurs.
D'après Sundberg (1974).
Les différences de qualité entre les voyelles parlées et chantées sont bien connues des chanteurs et des professeurs de chant. Ainsi, on conseille souvent aux étudiants en chant de modifier ou de "colorer" un /i:/ en /y:/, un /e:/ en /œ/, un /a:/ en /α:/, etc. Une stratégie courante pour les voix masculines consiste à "couvrir" les voyelles dans la partie supérieure de la gamme masculine ou à utiliser "l'accord des formants" (Doscher, 1994 ; Miller, 2008). Cela semble impliquer que le F1 est abaissé dans les voyelles qui ont normalement un F1 élevé, comme /a/ et /ae/. Pourtant, il est considéré comme important que, sur le plan perceptif, les chanteurs ne remplacent pas, mais modifient simplement une voyelle vers une autre voyelle. Cela signifierait que les voyelles chantées devraient conserver leur identité vocalique perceptive, bien que F1 et F2 soient quelque peu inhabituels.
Par rapport aux chanteurs ayant reçu une formation classique, les chanteurs de musique pop semblent dans l'ensemble produire des déviations beaucoup plus faibles par rapport aux qualités de voyelles utilisées dans la parole normale. Cependant, des écarts ont été observés dans certains genres non classiques également. Par exemple, dans une étude sur un seul sujet portant sur le style vocal appelé "twang" (un timbre de voix produit par des partiels aigus particulièrement forts), on a observé que F2 était en moyenne environ 10 % plus élevé, et F3 environ 10 % plus bas, que dans un mode de chant neutre (Sundberg & Thalén, 2010).
D. Classification de la voix
Les voix de chant sont classées en six groupes principaux : soprano, mezzo-soprano, alto, ténor, baryton et basse. Il existe également des sous-groupes couramment utilisés, comme la voix dramatique par opposition à la voix lyrique, ou encore la voix spinto, colorature, soubrette, etc. Le principal critère de cette classification est la gamme de fréquences confortables du chanteur. Si la tessiture d'un chanteur se situe entre C3 et C5 (131-523 Hz), il est classé ténor. Ces gammes se chevauchent dans une certaine mesure, et la gamme C4 à E4 (262-330 Hz) est en fait commune à toutes les classifications vocales. Néanmoins, même si nous entendons une voix chanter dans cette gamme de fréquences étroite, nous pouvons généralement entendre s'il s'agit d'une voix masculine ou féminine, et les experts peuvent même identifier la classification de la voix.
Cleveland (1977) a étudié le contexte acoustique de cette capacité de classification en ce qui concerne les chanteurs masculins. Il a présenté cinq voyelles chantées par huit chanteurs professionnels - basses, barytons ou ténors - à des professeurs de chant à qui il a demandé de classer les voix. Les résultats ont révélé que le principal indice acoustique dans la classification des voix était F0. Cela n'est pas très surprenant, si l'on suppose que les auditeurs se sont basés sur la caractéristique acoustique la plus apparente en premier lieu. Cependant, en comparant des voyelles chantées à la même hauteur, Cleveland a découvert que les fréquences des formants servaient d'indice secondaire. La tendance était la suivante : plus les fréquences des formants étaient basses, plus la gamme de fréquences du chanteur était supposée être basse. En d'autres termes, les basses fréquences formantes semblaient être associées aux chanteurs de basse et les hautes fréquences formantes aux ténors. Lors d'un test d'écoute ultérieur, Cleveland a vérifié ces résultats en présentant aux mêmes professeurs de chant des voyelles synthétisées avec des fréquences de formants qui variaient systématiquement en fonction de ses résultats du test qui utilisait des voyelles réelles.
Roers, Mürbe et Sundberg (2009) ont analysé les profils radiographiques de 132 chanteurs qui ont été acceptés pour une formation de chanteur soliste à la Hochschule für Musik de Dresde, en Allemagne, et ont mesuré les dimensions de leur conduit vocal et la longueur de leurs plis vocaux. Leurs résultats corroborent ceux rapportés précédemment par Dmitriev et Kiselev (1979), selon lesquels les voix graves ont tendance à avoir des conduits vocaux longs et vice versa. Ils ont également observé que cette différence dépend principalement de la longueur de la cavité du pharynx. Ainsi, les sopranos ont tendance à avoir les pharynx les plus courts et les basses les plus longs. Ils ont également noté que les plis vocaux étaient généralement plus courts dans les classifications avec une gamme de hauteur de son plus élevée et plus longs dans les classifications avec une gamme de hauteur de son plus basse. Cela suggère qu'à une hauteur de son donnée, les chanteurs dont la gamme de sons est plus élevée devraient avoir tendance à avoir une fondamentale de source vocale plus faible que les chanteurs dont la gamme de sons est plus faible, comme mentionné précédemment.
En résumé, les fréquences des formants, y compris la fréquence centrale du groupe de formants du chanteur, diffèrent de manière significative entre les principales classifications de la voix. Ces différences reflètent probablement des différences dans les dimensions du tractus vocal, en particulier les rapports de longueur entre le pharynx et la bouche.
V. Intensité et masquage
Les chanteurs d'opéra et de concert se produisant dans le style classique sont parfois accompagnés par un orchestre qui peut être assez fort ; le niveau sonore ambiant dans une salle de concert peut atteindre 90 à 100 dB. L'effet de masquage d'un son dépend fortement de la façon dont l'énergie sonore est répartie sur l'échelle des fréquences. Cette distribution peut être visualisée sous la forme d'un LTAS. Le spectre illustré à la figure 9 a été obtenu à partir d'un enregistrement du Vorspiel du premier acte de l'opéra Die Meistersinger de Wagner, et la plupart des musiques orchestrales de la culture occidentale produisent un LTAS similaire. Les composantes spectrales les plus fortes apparaissent généralement dans la région de 200 à 500 Hz, et au-delà de 500 Hz, la courbe chute d'environ 9 dB/octave, selon le volume de l'orchestre (Sundberg, 1972).
L'effet de masquage d'un son avec un LTAS comme celui illustré à la figure 9 est bien sûr plus important aux fréquences où le son masquant est le plus fort. Il diminue plus fortement en dessous qu'au-dessus de la fréquence du masqueur. Ainsi, en moyenne, l'effet de masquage du son de l'orchestre sera le plus important à 200-500 Hz et moins important pour les fréquences supérieures et surtout pour les fréquences inférieures.
L'autre courbe de la figure 9 montre une LTAS moyenne sur 15 voix masculines non entraînées lisant un texte standard à voix haute. Cette LTAS est étonnamment similaire à celle d'un orchestre, ce qui suggère que la combinaison d'un orchestre fort avec une voix humaine serait tout à fait malheureuse ; l'orchestre masquerait la voix. Et, inversement, si le son de la voix était beaucoup plus fort (ce qui est très peu probable), l'orchestre serait alors masqué. Par conséquent, les caractéristiques acoustiques de la voix humaine telles qu'observées dans le discours masculin fort ne sont pas utiles pour les chanteurs solistes accompagnés par un orchestre fort.
Revenons maintenant au cas du chant aigu. Dans ce cas, le spectre sera dominé par le fondamental si F1 est accordé sur une fréquence proche de F0, comme nous l'avons mentionné précédemment. On peut s'attendre à ce que cela se produise dès que F0 est supérieur à la valeur normale de F1, qui varie entre environ 300 et 800 Hz, selon la voyelle, comme l'illustre la figure 2. D'après ce qui a été décrit précédemment à propos du masquage, nous voyons que toutes les voyelles sont susceptibles d'être masquées par un orchestre fort, à condition que leur F0 soit inférieur à 500 Hz (inférieur à environ B4). Cependant, les voyelles /α, a, æ/, dont le premier formant est bien supérieur à 500 Hz, auront leur plus forte partielle au-dessus de 500 Hz, elles devraient donc être moins vulnérables au masquage.
En résumé, on peut s'attendre à ce que la voix d'une chanteuse soit masquée par un accompagnement orchestral fort si la hauteur est inférieure à B4 et si la voyelle n'est pas /a, a, æ/. Cela semble correspondre à l'expérience générale des voix féminines dans le chant d'opéra. Elles ne sont généralement pas difficiles à entendre lorsqu'elles chantent à des hauteurs élevées, même lorsque l'accompagnement orchestral est fort.
Comme nous l'avons vu précédemment, les chanteurs masculins de formation classique produisent un groupe de formants de chanteur, constitué d'un pic spectral élevé situé quelque part entre 2000 et 3000 Hz. Dans cette gamme de fréquences, le son d'un orchestre a tendance à être environ 20 dB plus faible que les partiels proches de 500 Hz, comme on peut le voir sur la figure 9. Par conséquent, le groupe de formants du chanteur est très susceptible de couper le son de l'orchestre. L'effet devrait être particulièrement fort si le chanteur fait face au public ; alors que les composantes à basse fréquence se dispersent de manière sphérique à partir de l'ouverture des lèvres, les composantes à haute fréquence sont rayonnées de manière plus sagittale, dans le prolongement de l'axe longitudinal de la bouche (Cabrera, Davis, & Connolly, 2011 ; Marshal & Meyer, 1985). Les composantes de basse fréquence sont susceptibles d'être absorbées dans les coulisses. Les partiels spectraux du groupe de formants du chanteur, en revanche, sont perdus dans une moindre mesure car leur rayonnement est plus limité à la direction sagittale. Par conséquent, si le chanteur fait face au public, les partiels du groupe de formants du chanteur seront plus forts que les partiels inférieurs du son qui atteint le public.
On peut mentionner deux exceptions au principe selon lequel les sons masqués par un son concurrent sont inaudibles. La première exception concerne le cas où le son le plus doux commence une fraction de seconde plus tôt que le son masquant (cf. Rasch, 1978 ; Palmer, 1989). L'autre exception s'applique à la situation où le son masquant varie dans le temps. Plomp (1977) a démontré que nous pouvons entendre un son masqué par intermittence comme étant continu si le signal de masquage est interrompu régulièrement (voir aussi le chapitre 6, ce volume, sur les effets sur l'asynchronie de l'apparition et la continuité auditive). Ces deux cas peuvent s'appliquer à la combinaison chanteur-orchestre. Un chanteur peut éviter le masquage en commençant les sons plus tôt que l'orchestre. De plus, un accompagnement orchestral, bien sûr, varie en intensité, ce qui peut aider la voix du chanteur à se faire entendre.
VI. Aspects du timbre de la voix
A. "Le placement
De nombreux chanteurs et professeurs de chant parlent de "placement" et de la nécessité de "projeter" ou de "concentrer" la voix pour qu'elle atteigne l'extrémité d'un large public. La projection a été étudiée par Cabrera et associés (2011), qui ont trouvé des raisons de conclure que le son émis par un chanteur peut être amené à changer en fonction de l'intention du chanteur de "projeter". Le placement peut être " vers l'avant ", ce qui est généralement considéré comme souhaitable, et " vers l'arrière ", ce qui est considéré comme indésirable. Vurma et Ross (2002) ont étudié les corrélats acoustiques de la projection vers l'avant et vers l'arrière. Ils ont d'abord effectué un test d'écoute dans lequel des sujets experts devaient déterminer si une triade chantée par différents chanteurs sur différentes voyelles était placée en avant ou en arrière. Ils ont ensuite mesuré les caractéristiques spectrales des triades classées comme placées en avant et en arrière et ont observé que F2 et F3 avaient tendance à être plus élevés dans les triades perçues comme placées en avant. Ils ont également noté que le groupe de formants du chanteur était plus important dans ces triades.
Le terme "placement" peut être lié au fait que F3 a tendance à baisser si la pointe de la langue est rétractée. L'augmentation du niveau du groupe de formants du chanteur peut être le résultat de l'augmentation de F2 et F3 ; une réduction de moitié de la séparation de fréquence entre deux formants augmentera automatiquement leurs niveaux de 6 dB (Fant, 1960).
Gibian (1972) a synthétisé des voyelles dans lesquelles il a fait varier F4 tout en gardant les autres formants constants. Un expert en chant a constaté que le "placement dans la tête" du son était le plus "avancé" lorsque F4 était à 2,7 kHz, soit seulement 0,2 kHz au-dessus de F3.
B. Intelligibilité du texte
Nous avons vu que les chanteuses gagnent considérablement en niveau sonore en abandonnant les fréquences de formants typiques de la parole normale lorsqu'elles chantent dans l'aigu. En même temps, F1 et F2 sont déterminants pour la qualité des voyelles. Cela conduit à la question de savoir comment il est possible de comprendre les paroles d'une chanson lorsqu'elle est interprétée avec les "mauvaises" F1 et F2.
Valeurs F2. On peut s'attendre à ce que l'intelligibilité des voyelles et l'intelligibilité des syllabes/du texte soient toutes deux perturbées. Cet aspect du chant a été étudié dans plusieurs recherches.
Pour rappeler les difficultés rencontrées dans le passé pour mettre en place des conditions expérimentales bien contrôlées, on peut mentionner une expérience menée par le phonéticien allemand Carl Stumpf (1926). Il a utilisé trois sujets chanteurs : un chanteur d'opéra professionnel et deux chanteurs amateurs. Chaque chanteur a chanté diverses voyelles à des hauteurs différentes, en tournant le dos à un groupe d'auditeurs qui essayaient d'identifier les voyelles. Les voyelles chantées par le chanteur professionnel étaient plus faciles à identifier. En outre, dans l'ensemble, les pourcentages d'identifications correctes ont chuté jusqu'à 50 % pour plusieurs voyelles chantées au diapason de G5 (784 Hz).
Depuis lors, de nombreuses recherches ont été consacrées à l'intelligibilité des voyelles et des syllabes chantées (voir, par exemple, Benolken & Swanson, 1990 ; Gregg & Scherer, 2006 ; Morozov, 1965). La figure 12 donne un aperçu des résultats en termes de pourcentage le plus élevé d'identifications correctes observées dans diverses recherches pour les voyelles indiquées aux hauteurs indiquées. Le graphique montre que l'intelligibilité des voyelles est raisonnablement précise jusqu'à environ C5, puis chute rapidement avec la hauteur de son pour atteindre environ 15% d'identification correcte à la hauteur de F5. La seule voyelle qui a été observée comme étant correctement identifiée plus fréquemment au-dessus de cette hauteur est /a/. Outre la hauteur et le registre, la position du larynx semble également affecter l'intelligibilité des voyelles (Gottfried & Chew, 1986 ; Scotto di Carlo & Germain, 1985).
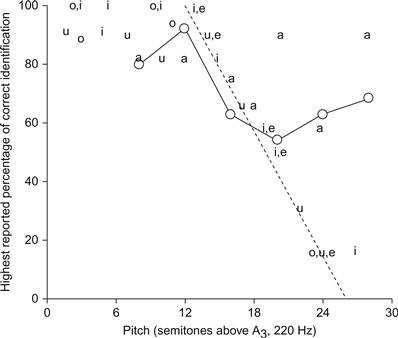
Figure 12 Pourcentage le plus élevé d'identifications correctes de voyelles observées à différentes hauteurs par Scotto di Carlo et Germain (1985), Sundberg (1977b), et Sundberg et Gauffin (1982). Les cercles ouverts montrent les données correspondantes pour les syllabes rapportées par Smith et Scott (1980).
Smith et Scott (1980) ont démontré de manière frappante l'importance des consonnes précédant et suivant une voyelle. Ceci est illustré dans le même graphique. Au-dessus de la hauteur de F5, l'intelligibilité des syllabes est clairement meilleure que celle des voyelles. Ainsi, les voyelles sont plus faciles à identifier lorsque le signal acoustique contient quelques transitions (Andreas, 2006). D'ailleurs, cela semble être un universel perceptif : les stimuli changeants sont plus faciles à traiter que les stimuli quasi-stationnaires.
Les difficultés d'identification des voyelles et des syllabes chantées à des hauteurs élevées résulteraient à la fois des déviations des chanteurs par rapport aux modèles de fréquence des formants de la parole normale et du fait que les voyelles aiguës contiennent peu de partiels largement distribués sur l'échelle de fréquence, produisant un manque d'information spectrale. En outre, un troisième effet peut contribuer. Selon le type de phonation, le F0 varie en amplitude. À une hauteur élevée, le F0 peut se situer entre le premier et le deuxième partiel. Sundberg et Gauffin (1982) ont présenté des voyelles synthétisées et soutenues dans la gamme soprano et ont demandé aux sujets d'identifier la voyelle. Les résultats ont montré qu'une augmentation de l'amplitude de la F0 était généralement interprétée comme une baisse de la F1.
Il semble probable que notre expérience de l'écoute de la parole influence notre identification des voyelles et des syllabes. Les enfants ont des conduits vocaux courts et des plis vocaux courts, de sorte qu'ils associent des fréquences de formants élevées à des hauteurs élevées. Quoi qu'il en soit, une meilleure similarité de la qualité des voyelles dans des conditions de F0 croissante peut être obtenue si un F0 élevé est combiné à un F1 élevé (Fahey, Diehl, & Traunmüller, 1996 ; Slawson, 1968).
Contrairement aux chanteurs de comédies musicales, les voix d'opéra de formation classique possèdent un groupe de formants de chanteur, comme décrit précédemment. Ce groupe renforce les partiels spectraux supérieurs, qui sont cruciaux pour l'identification des consonnes et donc pour l'intelligibilité des syllabes. Sundberg et Romedahl (2009) ont testé l'hypothèse selon laquelle les voix d'opéra masculines produiront une meilleure intelligibilité du texte que les chanteurs de comédie musicale en présence d'un bruit de masquage fort. Ils ont présenté des syllabes de test dans une phrase porteuse chantée par deux chanteurs professionnels des deux classifications dans un fond de bruit de babillage de fête, qui avait un LTAS similaire à celui d'un orchestre. On a demandé aux auditeurs d'identifier une syllabe test apparaissant dans la phrase porteuse. Il s'est avéré que les deux types de chanteurs réussissaient presque également, même si le son des voix d'opéra était beaucoup plus facile à discerner lorsque le bruit de fond était fort. Ainsi, on pouvait facilement discerner la voix mais pas le texte. Un facteur pertinent pourrait être que les chanteurs d'opéra ont produit des consonnes beaucoup plus courtes que les chanteurs de comédie musicale. Il est probable que les consonnes courtes soient plus difficiles à identifier en présence d'un bruit fort. Si c'est le cas, en allongeant la durée des consonnes, le chanteur de comédie musicale peut gagner en intelligibilité du texte, ce qu'il perdrait probablement en raison de l'absence d'un groupe de formants du chanteur.
C. Hauteur du larynx
La perception de la voix semble être influencée par la familiarité avec la production de sa propre voix. La constatation mentionnée précédemment selon laquelle l'intensité vocale perçue est plus étroitement liée à la pression sous-glottique qu'au NPS peut être considérée comme un signe que nous "entendons" par rapport à ce qui serait nécessaire pour produire les caractéristiques acoustiques que nous avons perçues. De même, d'autres dimensions perceptives de la qualité de la voix semblent physiologiques plutôt qu'acoustiques dans certaines conditions.
Le positionnement vertical du larynx semble en être un exemple. Les corrélats acoustiques des changements perçus dans la hauteur du larynx ont été étudiés dans une expérience de synthèse (Sundberg & Askenfelt, 1983). Les stimuli consistaient en une série de gammes ascendantes. Vers la fin de l'échelle, des signes acoustiques d'un larynx élevé étaient introduits en termes d'affaiblissement de la fondamentale de la source vocale, d'augmentation des fréquences des formants et de diminution de l'étendue du vibrato. Ces caractéristiques de stimulus ont été sélectionnées sur la base de mesures effectuées sur des voyelles produites avec des positions du larynx délibérément modifiées. Les stimuli ont été présentés à un groupe de professeurs de chant qui devaient décider si le chanteur imaginé levait ou non son larynx en chantant les notes supérieures de la gamme. Les résultats ont montré que la perception d'un larynx relevé était déclenchée plus efficacement par une augmentation des fréquences des formants. Cependant, la réduction de l'amplitude de la fondamentale a également favorisé l'impression d'un larynx élevé. De plus, une réduction de l'ampleur du vibrato y contribue, à condition que les amplitudes des fréquences des formants et de la F0 suggèrent déjà un larynx élevé.
Ces résultats ne sont pas surprenants, et ils illustrent certaines stratégies de perception. La forte dépendance aux fréquences des formants est logique, puisqu'un larynx relevé induit nécessairement une augmentation des fréquences des formants, c'est donc un signe fiable de larynx relevé. La réduction de l'amplitude de la fondamentale, cependant, est également un signe d'un changement vers une phonation plus pressée, et un tel changement n'accompagne pas nécessairement une élévation du larynx. Il est donc logique qu'il ne s'agisse pas d'une condition suffisante pour évoquer la perception d'un larynx surélevé, pas plus qu'une réduction de l'ampleur du vibrato.
D. L'identité du chanteur
Le timbre de la voix est déterminé par les caractéristiques spectrales, qui, à leur tour, sont déterminées par les fréquences des formants et la source de la voix, comme nous l'avons déjà mentionné. Les partiels des sons vocaux étant harmoniques, ils sont densément répartis sur l'échelle des fréquences, tant que F0 est faible. Les fréquences formantes varient selon les individus et caractérisent donc la voix d'une personne. À des fréquences basses, il devrait être facile pour un auditeur de reconnaître une personne à partir des pics de formants dans son spectre vocal. Cependant, si F0 est élevé, les partiels sont largement séparés le long du continuum de fréquences, et les formants seront difficiles à détecter.
C'est dans ce contexte que Molly Erickson et ses collaborateurs ont mené une série d'études (Erickson, 2003, 2009 ; Erickson & Perry, 2003 ; Erickson, Perry, & Handel, 2001). Elle a effectué des tests d'écoute dans lesquels elle a présenté des enregistrements de motifs à trois ou six notes chantés par divers chanteurs. Les stimuli étaient disposés selon une stratégie oddball, de sorte que deux des motifs étaient chantés par le même chanteur et le troisième par un chanteur différent. On demandait aux auditeurs de dire lequel était chanté par le chanteur différent. Les auditeurs n'ont souvent pas réussi à identifier correctement le cas particulier, notamment lorsque les stimuli présentaient une différence de hauteur substantielle, de sorte qu'une différence de hauteur était souvent interprétée comme le signe d'un chanteur différent. Les résultats étaient meilleurs pour les voix masculines que pour les voix féminines. Il est donc difficile de déterminer qui chante en écoutant seulement quelques notes, en particulier dans les aigus.
E. Naturalité
La synthèse est un outil précieux pour l'identification des corrélats acoustiques et physiologiques des qualités perceptives de la voix chantée. Par exemple, supposons que nous ayons trouvé un certain nombre de caractéristiques acoustiques d'une voix particulière sur la base d'un certain nombre de mesures. Toutes ces caractéristiques peuvent ensuite être incluses dans une synthèse, modifiées systématiquement et évaluées lors d'un test d'écoute. La synthèse ne sonnera exactement comme l'original que si toutes les propriétés acoustiques pertinentes sur le plan perceptif sont correctement représentées. En d'autres termes, la synthèse constitue un outil puissant pour déterminer dans quelle mesure la description acoustique d'une voix est perceptiblement exhaustive.
Dans les tests d'écoute avec des stimuli synthétisés, le caractère naturel est essentiel. Si les stimuli ne semblent pas naturels, la pertinence des résultats d'un test d'écoute risque d'être compromise. Le naturel perçu peut dépendre de caractéristiques spectrales tout à fait inattendues. La figure 13 en donne un exemple. Elle montre deux spectres de la même voyelle, l'un sonnant naturel et l'autre sonnant non naturel. Les spectres sont presque identiques. La différence, qui est acoustiquement discrète mais perceptiblement importante, consiste en un détail mineur dans la forme des pics des formants dans le spectre. La version qui ne semble pas naturelle avait des pics de formants trop émoussés. Il est intéressant que cette minuscule propriété spectrale soit importante sur le plan perceptif. Cependant, là encore, la stratégie perceptive est tout à fait logique. De tels pics spectraux émoussés ne peuvent jamais être générés par un conduit vocal humain et peuvent donc être considérés comme un critère fiable de manque de naturel.
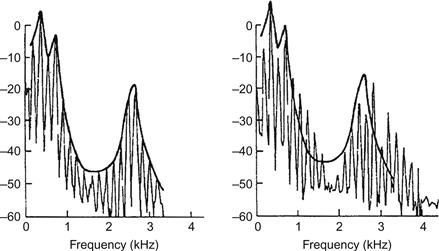
Figure 13 Spectres de la même voyelle sonnant clairement différemment en ce qui concerne le caractère naturel. Le spectre de gauche ne semble pas naturel, principalement parce que les pics des formants ont une forme irréaliste, les pentes des flancs n'étant pas assez concaves. Pour faciliter la comparaison, l'enveloppe spectrale du spectre gauche a été superposée au spectre droit.
D'après Sundberg (1989).
VII. Vibrato
A. Caractéristiques physiques
Le vibrato est présent dans la plupart des chants d'opéra et de concert occidentaux et souvent aussi dans la musique populaire. En général, il se développe plus ou moins automatiquement au cours de l'apprentissage de la voix (Björklund, 1961). Acoustiquement, il correspond à une ondulation presque sinusoïdale de F0 et peut donc être appelé vibrato de fréquence. Il peut être décrit en fonction de deux paramètres : (1) le taux, c'est-à-dire le nombre d'ondulations par seconde, et (2) l'étendue, c'est-à-dire la profondeur de la modulation exprimée en cents (1 cent est un centième de demi-ton). Plusieurs aspects du vibrato fréquentiel ont été étudiés (pour un aperçu, voir Dejonkere, Hirano, & Sundberg, 1995).
Selon Prame (1994, 1997), il se situe généralement entre 5,5 et 6,5 Hz, mais a tendance à s'accélérer quelque peu vers la fin d'un long ton soutenu. L'ampleur du vibrato dépend fortement du chanteur et du répertoire, mais se situe généralement dans une fourchette de ±30 cents à ±120 cents, la moyenne entre les tons et les chanteurs étant d'environ ±70 cents. Comme les spectres des sons vocaux sont harmoniques, les fréquences de tous les partiels varient en synchronisation avec le fondamental. L'amplitude de modulation d'un partiel dépend de la distance qui le sépare d'un formant, tandis que les fréquences des formants ne semblent pas varier sensiblement avec le vibrato (Horii, 1989). Par conséquent, l'amplitude de chaque partiel varie de manière synchrone avec le vibrato.
Dans la musique pop, un autre type de vibrato est parfois utilisé. Il correspond à une ondulation de l'intensité sonore, plutôt que du F0 et peut donc être appelé vibrato d'amplitude. Il y a des raisons de penser qu'il est généré par des ondulations de la pression sous-glottique. Il est différent du vibrato de fréquence des chanteurs d'opéra.
Le contexte physiologique du vibrato de fréquence a été décrit par Hirano et ses collègues (Hirano, Hibi, & Hagino, 1995). Des mesures électromyographiques sur les muscles du larynx ont révélé des pulsations en synchronisation avec le vibrato (Vennard, Hirano, Ohala, & Fritzell, 1970-1971). Les variations de l'innervation qui provoquent l'ondulation de la hauteur du son sont très probablement celles qui se produisent dans les muscles cricothyroïdiens qui lèvent la hauteur du son (Shipp, Doherty, & Haglund, 1990). En tant qu'effets secondaires induits, la pression sous-glottique et le flux d'air transglottique ondulent parfois en synchronisation avec le vibrato. De telles pulsations peuvent être observées dans certains enregistrements publiés par Rubin, LeCover, et Vennard (1967).
B. Aspects perceptifs
1. Intelligibilité des voyelles
À des fréquences élevées, les partiels spectraux sont très espacés le long du continuum de fréquences, et il est donc difficile de détecter où se trouvent les formants ; il se peut qu'il n'y ait aucun partiel près des formants. Il n'est pas déraisonnable de penser que le vibrato faciliterait l'identification des voyelles à des F0 élevées, puisque le vibrato fait bouger les partiels en fréquence et que les variations d'amplitude qui accompagnent les variations de fréquence donnent alors quelques indices sur la position des formants. Le principe simple est qu'un partiel croît en amplitude lorsqu'il se rapproche d'une fréquence de formants et diminue en amplitude lorsqu'il s'éloigne d'une fréquence de formants, comme l'illustre la figure 14. Le vibrato fréquentiel est donc accompagné d'oscillations d'intensité qui sont soit en phase, soit en contre-phase avec le F0, selon que le partiel le plus fort se situe juste en dessous ou juste au-dessus du F1. Une double mise en phase de l'intensité se produit lorsqu'une harmonique est proche de la fréquence du formant et se déplace à la fois au-dessus puis au-dessous du pic du formant pendant le cycle de vibrato. Ainsi, les relations de phase entre les ondulations de fréquence et d'amplitude d'un son avec vibrato nous renseignent en fait sur les emplacements de fréquence des formants. La question est donc de savoir si l'oreille peut détecter et utiliser ces informations. Si tel est le cas, le vibrato faciliterait l'identification des voyelles dans l'aigu.
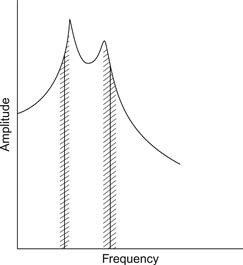
Figure 14 Illustration du fait que dans un son chanté avec un vibrato fréquentiel, l'amplitude et la fréquence d'un partiel spectral varient en phase ou en contre-phase, selon que le partiel est légèrement inférieur ou supérieur à la fréquence du formant le plus proche. La zone hachurée représente la largeur de la modulation de fréquence, et l'échelle de fréquence est linéaire.
D'après Sundberg (1995).
L'influence du vibrato sur l'identification de voyelles synthétisées avec une F0 entre 300 et 1000 Hz a été étudiée par Sundberg (1977b). Des sujets entraînés à la phonétique devaient identifier ces stimuli comme l'une des 12 voyelles longues suédoises. Les effets observés étaient généralement faibles.
Comme ce résultat semble contre-intuitif, McAdams et Rodet (1988) ont réalisé une expérience dans laquelle des sons avec et sans vibrato ont été présentés à quatre sujets. Les sons avaient des spectres identiques lorsqu'ils étaient présentés sans vibrato mais différaient lorsqu'ils étaient présentés avec vibrato. La figure 15 montre les spectres et les modèles de formants qu'ils ont utilisés pour obtenir cet effet. La tâche des sujets était de décider si deux stimuli présentés successivement étaient identiques ou non. Les sujets ont été capables d'entendre la différence entre les tons avec vibrato mais ont eu besoin d'un entraînement intensif pour entendre l'effet. Ces résultats suggèrent que le vibrato ne facilite normalement pas l'identification des voyelles dans une large mesure.
Figure 15 Spectres de stimulus et modèles de formants impliqués utilisés par McAdams et Rodet (1988) dans une expérience testant la pertinence de l'identification vibrato-voyelle ; le même spectre pouvait être obtenu par les deux modèles de fréquence de formants différents indiqués par les courbes en pointillés.
2. L'unicité de la tonalité
En général, il est bien établi que F0 détermine la hauteur. Dans le cas des sons avec vibrato, cependant, ce n'est pas tout à fait vrai. Bien que F0 varie régulièrement dans ces sons, la hauteur que nous percevons est parfaitement constante tant que le taux et l'ampleur du vibrato restent dans certaines limites. Quelles sont ces limites ? Ramsdell a étudié cette question à l'université de Harvard dans une thèse qui n'a malheureusement jamais été publiée. Ramsdell a fait varier systématiquement le taux et l'ampleur du vibrato et a demandé à des auditeurs de décider quand le son résultant possédait une "singularité de hauteur" optimale. Ses résultats pour un son de 500 Hz sont présentés à la figure 16.
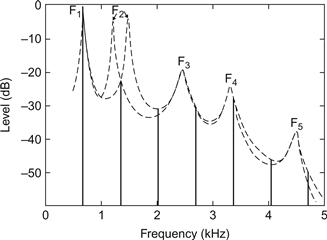
Figure 16 Valeurs de l'ampleur du vibrato produisant une "singularité de la hauteur" optimale à différents taux de vibrato (selon Ramsdell, voir texte). Les symboles encerclés indiquent la similarité maximale perçue avec la voix humaine obtenue par Gibian (1972). Les données de Ramsdell ont été obtenues avec une F0 de 500 Hz, alors que les données de Gibian se rapportent aux valeurs de F0 indiquées dans le graphique.
Plus tard, Gibian (1972) a étudié le vibrato dans des voyelles synthétiques. Il a fait varier le taux et l'étendue du vibrato et a demandé aux sujets d'évaluer la similarité de ce vibrato avec le vibrato produit par la voix humaine. Ses résultats correspondent étroitement aux données de Ramsdell, comme on peut le voir sur la figure. En plus de demander aux auditeurs de déterminer l'unicité de ton optimale, Ramsdell leur a également demandé d'évaluer la "richesse" du timbre. Ses données ont montré que l'optimum en ce qui concerne l'unicité de la hauteur et la richesse du timbre correspondait aux valeurs du taux et de l'étendue du vibrato généralement observées chez les chanteurs.
Il est intéressant de noter que la courbe de Ramsdell s'approche d'une ligne droite verticale au voisinage de sept ondulations par seconde. Cela implique que l'étendue du vibrato n'est pas très critique pour la singularité de la hauteur à ce rythme.
3. La hauteur et le F0 moyen
Un autre aspect perceptif du vibrato est la hauteur perçue. Si le taux et l'ampleur du vibrato sont maintenus dans des limites acceptables, quelle est la hauteur que nous percevons ? Cette question a été étudiée indépendamment par Shonle et Horan (1980) et Sundberg (1972, 1978b). Sundberg a demandé à des sujets entraînés musicalement de faire correspondre la hauteur d'un son avec vibrato en ajustant le F0 d'un son suivant sans vibrato. Les deux sons, qui étaient des voyelles chantées synthétisées, étaient identiques à l'exception du vibrato. Elles ont été présentées de manière répétée jusqu'à ce que l'ajustement soit terminé. Le taux de vibrato était de 6,5 ondulations par seconde, et l'étendue était de ±30 cents. La figure 17 montre les résultats. L'oreille semble calculer la moyenne de la fréquence d'ondulation, et la hauteur perçue correspond étroitement à cette moyenne.
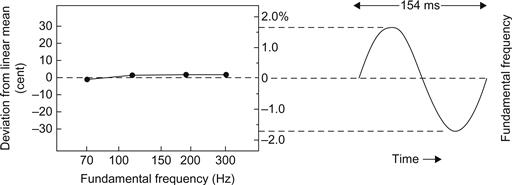
Figure 17 Panneau de gauche : F0 moyen d'une voyelle synthétisée sans vibrato que des sujets entraînés musicalement ont perçu comme ayant la même hauteur que la même voyelle présentée avec vibrato (après Sundberg, 1978b). Le panneau de droite montre la forme d'onde, le taux et l'étendue utilisés dans l'expérience.
Shonle et Horan ont utilisé des stimuli sinusoïdaux et sont arrivés pratiquement à la même conclusion. Cependant, ils ont également montré que c'est la moyenne géométrique plutôt que la moyenne arithmétique qui détermine la hauteur du son. La différence entre ces deux moyennes est très faible pour les vibratos musicalement acceptables.
On suppose souvent que le vibrato est utile dans la pratique musicale parce qu'il réduit les exigences en matière de précision du F0 (voir, par exemple, Stevens & Davis, 1938 ; Winckel, 1967). Une interprétation possible de cette hypothèse est que la hauteur d'un son avec vibrato est perçue avec moins de précision que la hauteur d'un son sans vibrato. Une autre interprétation est que l'intervalle de hauteur entre deux tons successifs est perçu moins précisément lorsque les tons ont du vibrato que lorsqu'ils n'en ont pas.
La première interprétation a été testée par Sundberg (1972, 1978a). Les écarts-types obtenus lorsque les sujets faisaient correspondre la hauteur d'un son avec vibrato avec la hauteur d'un son sans vibrato ont été comparés à ceux obtenus lors de correspondances similaires dans lesquelles les deux sons étaient sans vibrato. Comme on peut le voir sur la figure 18, les différences entre les écarts types étaient extrêmement faibles et diminuaient légèrement avec l'augmentation de F0. Cela implique que le vibrato réduit légèrement la précision de la perception de la hauteur pour les basses fréquences. D'un autre côté, les effets sont trop faibles pour expliquer tout effet mesurable dans la pratique musicale.
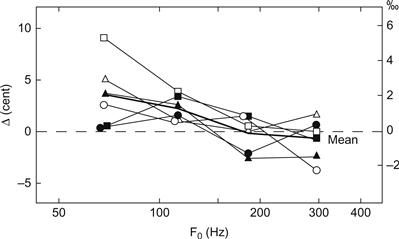
Figure 18 Effet du vibrato sur la précision de la perception de la hauteur en fonction de F0, observé lorsque des sujets entraînés musicalement ont d'abord fait correspondre la hauteur d'une voyelle de stimulus dépourvue de vibrato avec une voyelle de réponse ultérieure également dépourvue de vibrato, puis en répétant le test avec des voyelles de stimulus présentant un vibrato. L'ordonnée montre les différences d'écart-type obtenues entre ces deux conditions. Les symboles se rapportent aux sujets et la courbe lourde représente la moyenne du groupe.
D'après Sundberg (1978b).
La deuxième interprétation a été testée par van Besouw, Brereton et Howard (2008). Ils ont présenté à des musiciens des arpèges ascendants et descendants à trois tons. L'accord du ton central, avec ou sans vibrato, a été modifié et la tâche de l'auditeur était de décider quand il était accordé et quand il était désaccordé. Les résultats ont montré que la plage d'intonation acceptable du ton moyen était en moyenne d'environ 10 cents plus large lorsqu'il y avait du vibrato que lorsqu'il n'y en avait pas.
Il existe également un troisième avantage possible du vibrato, à savoir l'intonation de tons sonnant simultanément et formant un intervalle consonant. Si deux tons complexes aux spectres harmoniques sonnent simultanément et constituent un intervalle consonant parfaitement accordé, certaines partielles d'un ton coïncideront avec certaines partielles de l'autre ton. Par exemple, si deux sons de F0 200 et 300 Hz (c'est-à-dire produisant une quinte parfaite) sonnent simultanément, chaque troisième partiel du son inférieur coïncidera avec chaque deuxième partiel du son supérieur. Un désaccord de l'intervalle provoquera des battements. Ces battements disparaissent si l'un des tons présente un vibrato. Ainsi, si deux voix chantent parfaitement "droit" (c'est-à-dire sans vibrato), les exigences de précision par rapport au F0 sont plus élevées que si elles chantent avec vibrato.
Dans le chant colorature staccato, des tons plus courts que la durée d'un cycle de vibrato apparaissent parfois. d'Alessandro et Castellengo (1991) ont mesuré la hauteur perçue de ces tons courts. Il est intéressant de noter que la moitié ascendante d'un cycle de vibrato, lorsqu'elle est présentée seule, est perçue comme étant supérieure de 15 cents à la F0 moyenne, tandis que la moitié descendante est perçue comme étant inférieure de 11 cents à la moyenne. Les auteurs ont conclu que la fin d'un cycle de vibrato aussi court est plus significative pour la perception de la hauteur que son début.
Nos conclusions sont que la hauteur d'un son avec vibrato est pratiquement identique à la hauteur d'un son sans vibrato avec une F0 égale à la moyenne géométrique de la F0 du son avec vibrato. De plus, la précision avec laquelle la hauteur d'un son avec vibrato est perçue n'est pas affectée de manière appréciable par le vibrato.
VIII. L'intonation dans la pratique
Quelques études sur la perception de la hauteur des sons vibrato ont été mentionnées précédemment. Ces recherches ont été effectuées dans des conditions expérimentales bien contrôlées. Les résultats ainsi obtenus s'appliquent-ils également à la pratique musicale ? Une étude de la précision de F0 dans la pratique musicale est susceptible de répondre à cette question.
Dans une revue d'un certain nombre d'investigations, Seashore (1938/1967) a inclus une abondante documentation sur des enregistrements de F0 d'interprétations professionnelles de diverses chansons. La tendance était que les notes longues étaient chantées avec un F0 moyen qui coïncide avec la valeur théoriquement correcte. Ceci est en accord avec les résultats expérimentaux rapportés précédemment. En revanche, elles "commencent souvent légèrement à plat (environ 90 cents en moyenne) et sont progressivement corrigées pendant les 200 premières msec du ton". En outre, on a observé qu'un grand nombre de sons longs modifiaient leur fréquence moyenne de diverses manières au cours du son. Bjørklund (1961) a constaté que de telles déviations étaient typiques des chanteurs professionnels par rapport aux chanteurs non professionnels. Une interprétation possible de ce phénomène est que la hauteur du son est utilisée comme un moyen d'expression musicale.
En ce qui concerne les sons courts, la relation entre F0 et la hauteur semble être considérablement plus compliquée. Le cas est illustré à la figure 19, qui montre le schéma des F0 pendant un passage de colorature tel que chanté par un chanteur masculin. Le chanteur a jugé cette performance acceptable. L'enregistrement révèle une coordination minutieuse de l'amplitude, du vibrato et du F0. Chaque note prend une période de vibrato, et la plupart des périodes de vibrato semblent encercler approximativement la fréquence cible.
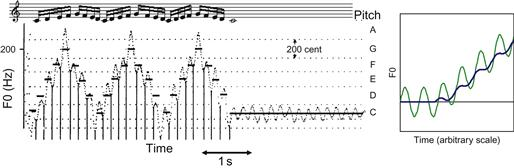
Figure 19 Gauche, F0 de l'interprétation par un chanteur professionnel du passage colorature illustré en haut. Les lignes horizontales en pointillés représentent les fréquences situées à mi-chemin entre les fréquences centrales des tons de la gamme, calculées selon l'accord à tempérament égal, en utilisant la F0 moyenne du C3 final comme référence. A droite, la courbe fine montre la courbe F0 résultant de la superposition d'une sinusoïde sur une rampe. La courbe lourde montre la moyenne mobile obtenue avec une longueur de fenêtre du cycle de l'onde sinusoïdale.
Selon Seashore (1938/1967), l'oreille musicale est généreuse et fonctionne sur le mode interprétatif lorsqu'elle écoute du chant. D'un autre côté, il y a certainement des limites à cette générosité. De plus, ce qui semble être de la générosité peut être une sensibilité à de petites déviations délibérées et significatives de ce qui est théoriquement "correct".
Sundberg, Prame et Iwarsson (1996) ont étudié les F0 moyens acceptés comme étant "accordés" et "désaccordés" dans 10 enregistrements commerciaux d'une chanson qui ont été présentés à des auditeurs experts sur une cassette d'écoute. Un tableau contenant la partition des extraits a été remis aux auditeurs, et il leur a été demandé d'encercler chaque note qu'ils percevaient comme étant "désaccordée". La moyenne des F0 a été calculée pour chaque note. Ces fréquences moyennes ont ensuite été rapportées à l'accord tempéré égal, en utilisant l'accord de l'accompagnement comme référence. Les résultats ont montré une assez grande variabilité dans les jugements. L'analyse des cas clairs, c'est-à-dire des sons qui ont été acceptés comme étant accordés par tous les experts ou jugés comme étant désaccordés par la plupart des auditeurs, a révélé que pour la plupart des sons acceptés comme étant accordés, la F0 moyenne variait dans une bande d'environ ±7 cents, alors que la plupart des sons jugés comme étant désaccordés se trouvaient en dehors de cette bande de fréquence plutôt étroite. De plus, les bandes correspondant aux tons perçus comme étant accordés ne correspondaient pas toujours aux F0 de l'accordage à tempérament égal. De plus, pour certaines tonalités, la F0 moyenne acceptée comme étant accordée variait considérablement. Ces sons semblaient être marqués harmoniquement ou mélodiquement. La plupart des chanteurs semblaient adhérer à certains principes dans leurs déviations de l'accord à tempérament égal. L'un d'entre eux consistait à chanter les sons aigus de façon aiguë, c'est-à-dire à ajouter une correction de F0 qui augmentait avec la hauteur. L'autre consistait à aiguiser et à aplatir les tons situés du côté de la dominante (droite) et de la sous-dominante (gauche) du cercle des quintes, où la racine de l'accord dominant était la référence "12 heures". Ainsi, les écarts par rapport aux fréquences des tons de la gamme selon l'accord tempéré égal semblent systématiques.
Sundberg, Lã et Himonides (2011) ont analysé l'accordage de chanteurs barytons de premier plan et ont trouvé des exemples de déviations assez importantes par rapport à l'accordage tempéré égal, dépassant parfois 50 cents. En particulier, la note la plus aiguë dans les phrases à caractère émotionnel agité était souvent aiguisée. L'intonation de ces notes a été ramenée à l'accord tempéré égal, et un test d'écoute a été effectué dans lequel des musiciens auditeurs ont été invités à évaluer l'expressivité dans des comparaisons par paires de la version originale et de la version avec l'accord manipulé. Une préférence significative a été observée pour les versions originales. Ce résultat indique que l'intonation peut être utilisée comme un dispositif expressif dans le chant. De tels écarts significatifs par rapport à l'accord à tempérament égal sont également utilisés comme moyens expressifs dans la musique instrumentale (Fyk, 1995 ; Sirker, 1973 ; Sundberg, Friberg & Frydén, 1991).
Comme nous l'avons mentionné précédemment, l'exécution sans vibrato d'intervalles consonants mal accordés avec des tons sonnant simultanément donne lieu à des battements, et les battements sont généralement évités dans la plupart des types de musique. En ajoutant le vibrato, le chanteur échappe aux battements. Par conséquent, le vibrato semble offrir au chanteur l'accès à l'intonation comme moyen expressif.
IX. Expression
L'expressivité est souvent considérée comme l'un des aspects les plus essentiels du chant, et elle a été analysée dans un grand nombre de recherches (pour une revue, voir Juslin & Laukka, 2003). L'accent a surtout été mis sur les émotions de base, telles que la colère, la peur, la joie, la tristesse et la tendresse. Seuls quelques exemples des résultats rapportés dans ces recherches sont examinés ici.
La communication des émotions de base fonctionne assez bien dans le chant. Environ 60% à 80% d'identifications correctes ont été observées dans des tests d'écoute à choix forcé concernant des humeurs comme la colère, la peur et la joie (Kotlyar & Morozov, 1976 ; Siegwarth & Scherer, 1995).
Les détails de la performance qui contiennent les messages du chanteur concernant les émotions ont été étudiés par Kotlyar et Morozov (1976). Ils ont demandé à des chanteurs d'interpréter une série d'exemples afin de représenter différentes humeurs. Ils ont noté des effets importants sur le tempo et l'intensité sonore globale et ont également observé des modèles temporels caractéristiques dans la hauteur et l'amplitude, ainsi que des micropauses entre les syllabes. Siegwarth et Scherer (1995) ont observé que la production du ton du chanteur est également pertinente, en particulier la dominance du fondamental et les amplitudes des partiels élevés. Rapoport (1996) a constaté que les chanteurs utilisent tout un "alphabet" de différents modèles de F0 à des fins expressives. Par exemple, certains sons s'approchent de leur valeur cible par un glissement ascendant rapide ou lent, tandis que d'autres atteignent leur F0 cible dès le début du son.
Dans la plupart des études sur la coloration émotionnelle du chant, le caractère agité ou paisible est une dimension dominante. Sundberg, Iwarsson et Hagegård (1995) ont comparé les performances d'un ensemble d'extraits musicaux chantés sans accompagnement par un chanteur d'opéra professionnel. Le chanteur a chanté les extraits de deux manières, soit comme lors d'un concert, soit aussi vide d'expression musicale qu'il le pouvait. On a observé un certain nombre de caractéristiques qui semblaient différencier les extraits agités des extraits paisibles. Ainsi, dans les exemples agités, les changements de niveau sonore étaient plus rapides, le volume vocal était plus élevé, le tempo était plus rapide et l'amplitude du vibrato était généralement plus grande que dans les exemples paisibles, en particulier dans les versions expressives. Dans les extraits avec une ambiance calme, les différences inverses ont été observées entre les versions expressives et neutres. Ainsi, le chanteur a accentué la différence entre agité et paisible dans les versions concertantes.
Quelles informations sont véhiculées par l'expressivité ? Le marquage des phrases semble être un principe important, qui ne semble cependant pas faire la différence entre expressif et neutre. Un autre principe semble être de mettre en valeur les différences entre les différentes catégories de tonalités telles que les tonalités de la gamme, les intervalles musicaux et les valeurs des notes ; l'accentuation de la pointe d'une phrase décrite précédemment peut être considérée comme un exemple de ce principe. Un troisième principe consiste à mettre en valeur les tonalités importantes. En chantant avec expression, les chanteurs peuvent donc aider l'auditeur à accomplir trois tâches cognitives : (1) se rendre compte des tons qui vont ensemble et où se trouvent les limites structurelles, (2) mettre en évidence les différences entre les catégories de tons et d'intervalles, et (3) mettre en valeur les tons importants.
De toute évidence, les chanteurs utilisent un code acoustique pour ajouter de l'expressivité à une performance. Comme le soulignent Juslin et Laukka (2003), ce code est similaire à celui utilisé dans la parole ; en fait, il serait très surprenant que des codes différents soient appliqués dans la parole et dans le chant afin de transmettre la même information. Par exemple, le ralentissement du tempo vers la fin des phrases musicales est similaire au principe d'allongement final utilisé dans la parole pour marquer la fin d'unités structurelles telles que les phrases. De même, dans le chant comme dans la parole, une syllabe ou un ton important peut être mis en valeur en allongeant son temps fort (Sundberg et al., 1995). Cependant, le code expressif utilisé dans le chant n'est pas nécessairement simplement importé de celui utilisé dans la parole. Comme le souligne avec charme Fonagy (1967, 1976, 1983), l'origine réelle de tous les changements dans les sons vocaux est la forme du conduit vocal et l'ajustement de l'appareil des plis vocaux ; l'organe vocal ne fait que traduire le mouvement en changements sonores. Fonagy soutient que l'expressivité de la parole dérive d'un comportement pantomimique de ces organes. Par exemple, dans la tristesse, la langue adopte un mouvement lent et déprimé qui imprime ses propres caractéristiques aux séquences sonores qui en résultent.
X. Remarques finales
Dans le présent chapitre, nous avons examiné deux types de faits concernant le chant. Le premier est le choix des caractéristiques acoustiques des voyelles que les chanteurs apprennent à adopter et qui représentent des déviations typiques de la parole normale. Trois exemples de telles caractéristiques ont été discutés : (1) le choix des fréquences des formants en fonction de la hauteur du son dans le chant aigu, (2) le groupe de formants du chanteur qui apparaît typiquement dans tous les sons vocaux de la voix masculine classiquement entraînée, et (3) le vibrato qui apparaît dans le chant masculin et féminin.
Il y a de bonnes raisons de supposer que ces caractéristiques servent un objectif spécifique. Les fréquences des formants dépendant de la hauteur ainsi que le groupe de formants du chanteur sont tous deux des phénomènes résonatoires qui augmentent l'audibilité de la voix du chanteur en présence d'un accompagnement orchestral fort. Comme les phénomènes résonatoires se produisent indépendamment de l'effort vocal, l'augmentation de l'audibilité est obtenue sans dépense en termes d'effort vocal ; par conséquent, un objectif probable dans ces deux cas est l'économie vocale. Le vibrato semble avoir pour but de permettre au chanteur une plus grande liberté en matière d'intonation, puisqu'il élimine les battements avec le son d'un accompagnement sans vibrato. Ainsi, dans ces trois cas, le chant se distingue de la parole de manière très adéquate. Il est tentant de spéculer que ces caractéristiques sont le résultat de l'évolution ; les chanteurs qui les ont développées ont connu le succès, et donc leurs techniques ont été copiées par d'autres chanteurs.
Un deuxième type de fait concernant le chant, abordé dans ce chapitre, concerne les corrélats acoustiques de diverses classifications vocales dont on peut supposer qu'elles sont basées sur la perception. Ces classifications ne sont pas seulement ténor, baryton, basse, et ainsi de suite, mais aussi l'effort vocal (par exemple, piano, mezzo piano), et le registre. Nous avons vu que dans la plupart de ces cas, il était difficile de trouver un dénominateur acoustique commun, car les caractéristiques acoustiques des catégories varient avec la voyelle et le F0. Le dénominateur commun semble plutôt exister à l'intérieur du corps. Dans le cas de la classification des voix masculines - ténor, baryton et basse - les différences caractéristiques de la fréquence des formants seraient le résultat de différences morphologiques dans la longueur du conduit vocal et des plis vocaux. Il en va de même pour l'effort vocal et le registre, car ils reflètent des différences dans le contrôle et le fonctionnement des plis vocaux. Par conséquent, ces exemples de classification de la voix semblent reposer sur les propriétés des structures des voies aériennes plutôt que sur les propriétés acoustiques spécifiques des sons vocaux. Ceci est probablement révélateur par rapport à la façon dont nous percevons les voix chantées. Nous semblons interpréter ces sons en fonction de la manière dont le système de production de la voix a été utilisé pour les créer.
En ce qui concerne l'interprétation artistique, il semble qu'elle contienne au moins trois composantes différentes. La première est la différenciation des différents types de notes, comme les tons de la gamme et les valeurs des notes. Une autre composante est le marquage des limites entre les constituants structurels tels que les motifs, les sous-phrases et les phrases. Ces exigences de la performance chantée semblent s'appliquer à la fois à la parole et à la musique et sont susceptibles d'avoir été développées en réponse aux propriétés du système perceptif humain. La troisième composante est la signalisation de l'ambiance émotionnelle du texte et de la musique. À cet égard également, la perception du chant semble être étroitement liée à la perception de la parole. Le codage des émotions dans la parole et le chant serait similaire et probablement fondé sur un "langage corporel" pour la communication des émotions. Si cela est vrai, notre connaissance du comportement émotionnel humain, et en particulier de la parole, nous sert de référence pour décoder les informations émotionnelles du chant.


