Dans ce chapitre, nous décrivons comment les approches de la linguistique de corpus peuvent être appliquées à l'analyse du discours. La linguistique de corpus est un ensemble de méthodologies de recherche qui se concentrent sur la description des modèles linguistiques d'utilisation dans des collections de textes conçus pour représenter un domaine de discours cible (le corpus), en utilisant des programmes informatiques automatiques et interactifs pour faciliter les analyses quantitatives et qualitatives. Au cours des dernières décennies, les approches par corpus se sont imposées dans de nombreux sous-domaines de la linguistique, et l'analyse du discours ne fait pas exception. Dans une enquête menée auprès de trois grandes revues spécialisées dans le discours (Discourse Processes, Discourse Studies et Text & Talk), 43 % de tous les articles de recherche publiés en 2014 faisaient état de recherches empiriques fondées sur des corpus (Egbert, Biber et Gray à paraître).
Le terme "discours" lui-même défie une définition singulière. Dans un effort pour donner un sens aux diverses façons dont le "discours" a été conceptualisé, Schiffrin et al. (2001 : 1) regroupent les conceptualisations en trois catégories principales :
- Le discours en tant que langue utilisée, qui étudie la variation de l'utilisation des formes linguistiques et des constructions linguistiques traditionnelles ;
- Le discours en tant que structure linguistique au-delà du niveau de la phrase, qui se concentre sur la structure plus large du texte, c'est-à-dire sur les manières systématiques dont les textes sont construits ; et
- Le discours en tant que pratiques sociales et idéologies associées au langage et/ou à la communication.
Les méthodes linguistiques du corpus ont été appliquées pour comprendre la nature du discours à partir de chacune de ces trois perspectives. Dans les deux premières perspectives, l'accent est mis explicitement sur la forme linguistique d'un texte ou d'un ensemble de textes. Étant donné que de nombreuses études basées sur des corpus se concentrent sur les formes linguistiques dans des contextes linguistiques et/ou situationnels spécifiques, et cherchent à identifier les modèles de variation linguistique qui sont généralisables à travers les textes dans un domaine discursif spécifique, la recherche en linguistique de corpus adopte souvent l'approche de la langue en usage. Cependant, comme nous le verrons dans la dernière section, la linguistique de corpus a également été utilisée pour étudier la structure des textes, et des recherches récentes basées sur des corpus ont fait le lien entre la langue en usage et la langue au-delà de la phrase (c'est-à-dire la structure des textes) en étudiant les réalisations linguistiques des unités textuelles et la distribution des caractéristiques linguistiques dans les textes.
Les approches par corpus ont également été appliquées à des recherches basées sur la troisième perspective du discours, afin d'examiner " comment les phénomènes sociaux et politiques sont représentés et construits dans les produits culturels d'une société " (Partington et Marchi 2015 : 219), en particulier sous l'égide des études de discours assistées par corpus (CADS ; Partington et Marchi 2015) et de l'analyse critique du discours basée sur le corpus (CDA ; par exemple Baker et al. 2008). Les études s'inscrivant dans cette tradition associent généralement la " lecture attentive ", plus qualitative, de textes ou d'exemples linguistiques à la nature quantitative des données linguistiques de corpus, telles que les listes de fréquences, les mots-clés et les lignes de concordance (Partington et Marchi, 2015). Cette approche est de plus en plus utilisée pour explorer des préoccupations sociales, telles que :
- La construction de valeurs et de préjugés dans le discours sur les nouvelles (par exemple, Bednarek et Caple 2017),
- Le discours sur la santé mentale et physique (par exemple, Baker, Brookes et Evans 2019),
- Le genre et la sexualité (par exemple, Baker et Balirano 2017 ; Baker et Levon 2016),
- L'inégalité économique (par exemple, Gomez-Jimenez et Toolan 2020) et
- Les questions politiques et religieuses (par exemple, Zuccato et Partington 2018 sur le Brexit).
Parce qu'il ne serait pas possible de fournir une couverture complète de ces trois approches du discours, le reste de ce chapitre se concentrera principalement sur la recherche sur corpus qui considère le langage en usage et le langage au-dessus de la phrase. Les lecteurs sont invités à consulter Baker (2006) et Partington et Marchi (2015) pour des introductions complètes à la troisième perspective.
L'objectif de ce chapitre est de présenter la linguistique de corpus comme une méthode d'analyse du discours, en se concentrant principalement sur les analyses de la langue en usage basées sur la forme et la fonction. Nous décrivons d'abord les caractéristiques clés des méthodologies de la linguistique de corpus en relation avec son utilisation pour l'analyse du discours. Ensuite, nous présentons une étude de cas portant sur l'élaboration structurelle dans des écrits et des conversations universitaires, illustrant une approche basée sur le corpus pour étudier le discours en tant que langue en usage. Dans la section 4, nous étendons notre discussion aux études qui prennent en compte la structure du texte (le discours au-delà de la phrase) et les caractéristiques linguistiques de la composition structurelle des textes.
RECHERCHE SUR LA LANGUE EN USAGE PAR L'ANALYSE DE CORPUS
Au cours des dernières décennies, le développement de la linguistique de corpus en tant qu'approche méthodologique de l'analyse linguistique descriptive a fourni un moyen de faire des découvertes généralisables sur l'utilisation de la langue dans divers types de discours. En tant qu'approche méthodologique, la linguistique de corpus présente les caractéristiques suivantes (Biber et al. 1998 : 4) :
- L'approche est empirique. Les résultats sont basés sur des modèles d'utilisation réels et observés dans des textes naturels.
- La base de l'analyse est le corpus, une collection de textes conçue pour être représentative d'un domaine cible.
- Les ordinateurs sont utilisés pour analyser (ou faciliter l'analyse) le corpus, en utilisant des techniques automatiques et interactives.
- L'analyse est à la fois quantitative et qualitative par nature.
L'objectif principal de nombreuses études du discours basées sur des corpus est de documenter la variation de l'utilisation des caractéristiques lexicales et grammaticales dans des registres particuliers, en décrivant les fonctions et les distributions de fréquence de ces caractéristiques linguistiques. Les quatre caractéristiques présentées ci-dessus distinguent les méthodologies de la linguistique de corpus des autres approches d'analyse du discours, et constituent la base des contributions uniques que les études de corpus peuvent offrir.
Les contributions de la linguistique de corpus à l'analyse du discours
La principale caractéristique d'une approche basée sur les corpus est peut-être la plus évidente : elle est basée sur un corpus, une grande collection de textes électroniques qui est principalement échantillonnée de manière raisonnée pour représenter un domaine discursif cible. De nombreux termes ont été utilisés pour distinguer les types de domaines discursifs (ou variétés de langue), notamment le registre, le genre, le style et le type de texte.1 Nous utilisons le terme registre pour désigner les variétés d'utilisation de la langue que l'on peut distinguer en fonction de caractéristiques situationnelles telles que l'objectif, le mode, le contexte, l'auteur/le locuteur, le lecteur et ainsi de suite (voir Biber et Conrad 2019). Par exemple, la conversation se caractérise par son mode oral en temps réel, le partage du temps et du lieu entre les participants et sa nature hautement interactive, entre autres. L'écriture académique, en revanche, est définie par son mode écrit, son édition, l'absence de temps et de lieu partagés entre les participants et son objectif hautement informatif. La contribution essentielle d'une approche du discours par corpus est que, parce que le corpus est un échantillon fondé sur des principes et conçu spécifiquement pour représenter le domaine cible, l'intention est que les résultats soient généralisés de manière significative au domaine (ou registre) du discours dans son ensemble. Plutôt qu'une analyse d'un seul ou d'un petit nombre de textes, les études de corpus peuvent examiner efficacement une grande collection de textes, dans le but d'apprendre sur le domaine plus largement plutôt que sur des textes spécifiques.
Comme les études de corpus sont basées sur ces grands échantillons de langue, les analystes s'appuient sur une variété d'outils informatiques pour les aider à analyser le corpus. Comme un ordinateur doit arriver à la même conclusion sur une caractéristique linguistique particulière chaque fois qu'il la rencontre, la fiabilité de l'analyse assistée par ordinateur est généralement assez élevée, ce qui permet au chercheur de se concentrer sur l'interprétation des données linguistiques. En outre, et c'est peut-être encore plus important, l'efficacité offerte par les ordinateurs signifie qu'une quantité beaucoup plus importante de données linguistiques peut être analysée. En raison de la grande quantité de données linguistiques disponibles, le calcul de modèles quantitatifs d'utilisation (en plus des analyses qualitatives et fonctionnelles) est significatif et, en fait, relativement efficace et fiable à réaliser.
L'utilisation de données quantitatives dans l'analyse du discours sur corpus est importante pour deux raisons principales. Premièrement, les méthodes quantitatives permettent l'établissement empirique de modèles linguistiques à travers les textes du corpus. En d'autres termes, le chercheur peut identifier des modèles de variation qui sont cohérents à travers les textes du corpus, réduisant ainsi le risque qu'une analyse soit une description inexacte d'un domaine ou que les résultats soient biaisés par un texte particulier ou un petit nombre de textes. Deuxièmement, en raison de la capacité à décrire un domaine de discours dans son ensemble (en termes quantitatifs et sur la base d'un grand nombre de textes représentatifs), il devient tout à fait possible d'effectuer des comparaisons entre domaines/registres. Ces comparaisons vont au-delà de la description d'une caractéristique linguistique particulière, pour documenter les distributions relatives de nombreuses caractéristiques lexicales et grammaticales dans toute variété de langue.
Bien entendu, un domaine/registre ne peut être entièrement décrit en termes quantitatifs uniquement. La clé de l'application de la linguistique de corpus est la conviction que la variation linguistique est à la fois systématique et fonctionnelle et peut être expliquée en considérant les associations fonctionnelles entre la situation d'utilisation et les caractéristiques linguistiques. Ainsi, un deuxième objectif clé de la recherche en linguistique de corpus est d'expliquer les modèles quantitatifs de variation en relation avec les fonctions communicatives des caractéristiques linguistiques dans le discours, et comment ces fonctions correspondent aux besoins d'une situation communicative (comme illustré dans la section 3 ci-dessous).
En résumé, la contribution essentielle des approches linguistiques de corpus à l'analyse du discours est la capacité de faire des découvertes fiables et généralisables sur les modèles de variation linguistique au sein et entre les domaines du discours. La conception et la représentativité des corpus sont essentielles à la généralisation des résultats de la recherche sur les corpus. La représentativité fait référence à la mesure dans laquelle les modèles linguistiques découverts dans un corpus peuvent être généralisés avec précision au domaine de discours cible. Ainsi, les corpus doivent être conçus et échantillonnés d'une manière qui garantit qu'ils représentent fidèlement les textes dans le registre/domaine d'utilisation (voir Egbert et al. à venir pour un traitement complet de la représentativité).
Études sur corpus de la langue d'usage
Dans le cadre général de la langue en usage, les études de discours basées sur des corpus ont examiné une grande variété de caractéristiques linguistiques à des niveaux linguistiques multiples, en adoptant souvent une vision fonctionnelle de la langue. Cet accent mis sur la fonction contribue à notre compréhension de la façon dont les choix linguistiques sont associés à des domaines discursifs particuliers, comment ils remplissent des fonctions communicatives importantes dans leurs contextes discursifs et comment un domaine peut être décrit pour ses caractéristiques particulières.
Une ligne générale de recherche cherche à décrire l'utilisation de caractéristiques linguistiques spécifiques et leurs fonctions discursives dans et à travers les registres. Les études basées sur des corpus ont porté sur des aspects du lexique et de la phraséologie, comme les études de collocation (la cooccurrence de mots particuliers). Par exemple, Yamasaki (2008) examine comment des collocations particulières de noms anaphoriques correspondent à différentes fonctions discursives dans les domaines de l'oral et de l'écrit. Les analyses de mots-clés (qui identifient les éléments lexicaux statistiquement distinctifs dans les corpus) sont couramment utilisées comme moyen d'identifier les idéologies, les préjugés et les représentations dans le discours (par exemple, Baker 2018).
De nombreuses recherches se sont concentrées sur d'autres types de langage récurrent, tels que les séquences continues connues sous le nom de paquets lexicaux (Biber et al. 1999 : Chapitre 13) et les séquences discontinues connues sous le nom de cadres (Gray et Biber 2013 ; Römer 2010). Outre la mise en évidence de la variation marquée des profils phraséologiques du discours oral et écrit (par exemple, Biber, Conrad et Cortes 2004), de nombreuses recherches se sont concentrées sur les fonctions discursives de ces caractéristiques phraséologiques. Une série de taxonomies fonctionnelles caractérisent le rôle que les unités phraséologiques jouent dans le discours (par exemple, le cadre de 2004 de Biber et al. sur les groupes de positions, de références et d'organisation du discours, ou les groupes de 2008 de Hyland axés sur la recherche, le texte et la participation dans les écrits universitaires). Les faisceaux ont également été associés à des fonctions plus spécifiques, telles que la cohésion et la signalisation du discours dans les conférences universitaires (Nesi et Basturkmen 2006). Dans de nombreux cas, une grande partie de cette recherche serait impossible sans les méthodologies de corpus permettant de découvrir de manière inductive la configuration fréquente et récurrente des éléments lexicaux dans le discours.
Les études de la grammaire dans le discours basées sur les corpus sont également répandues, et se concentrent souvent sur les modèles de distribution des caractéristiques grammaticales dans le discours, les facteurs influençant la variabilité de la grammaire, et les fonctions discursives des caractéristiques grammaticales. Ces études se répartissent en trois grandes catégories :
- Une focalisation sur une seule caractéristique ou construction linguistique et son utilisation dans le discours, comme Flowerdew et Forest (2015) sur les noms de signalisation ;
- L'examen d'un groupe de caractéristiques grammaticales qui contribuent à une seule fonction discursive, comme la position (Biber 2006) et l'engagement (Zou et Hyland 2020) ; et
- Une focalisation sur les profils grammaticaux généraux qui caractérisent un domaine ou un registre du discours, souvent par le biais d'une analyse multidimensionnelle (Biber 1988) pour découvrir les modèles de cooccurrence d'une gamme complète de caractéristiques linguistiques.
Indépendamment des caractéristiques linguistiques analysées, les études de discours sur corpus peuvent se concentrer sur un domaine discursif particulier, souvent du point de vue de l'anglais à des fins spécifiques ou de l'anglais à des fins académiques. Staples (2015), par exemple, effectue des analyses linguistiques multiples pour caractériser le discours des interactions infirmière-patient, en établissant des liens entre les modèles linguistiques et le succès de ces interactions. Les chapitres de Pickering et al. (2016) offrent des descriptions basées sur des corpus du discours sur le lieu de travail dans une série de contextes, tandis que les chapitres de Römer et al. (2020) se concentrent sur une série de registres académiques.
Les analyses basées sur des corpus sont idéalement adaptées aux comparaisons de l'utilisation de constructions linguistiques dans différents domaines. Même lorsque l'accent est mis sur un seul domaine, la comparaison entre les sous-composantes de ce domaine est courante (par exemple, Friginal 2009 utilise l'analyse MD pour décrire le discours des centres d'appels, tout en considérant simultanément la variabilité entre les agents et les appelants, les locuteurs masculins et féminins, et une série d'autres facteurs).
La prévalence des analyses comparatives dans les approches basées sur les corpus s'explique en partie par les données quantitatives précises fournies par les études de corpus et par la possibilité de collecter des corpus importants et représentatifs d'une variété de registres. La recherche sur corpus dans son ensemble a montré que des modèles différentiels de variation entre les registres existent pour une seule caractéristique linguistique ainsi que pour des ensembles de caractéristiques co-occurrentes. Pour cette raison, de nombreuses études basées sur des corpus prennent en compte les différences de registre dans leur description de la distribution et des utilisations fonctionnelles des constructions linguistiques. À titre d'exemple, la Longman Grammar of Spoken and Written English (Biber et al. 1999 ; republié sous le nom de Biber et al. 2021) est une grammaire de référence complète basée sur un corpus qui documente la façon dont toute caractéristique grammaticale de l'anglais est distribuée et utilisée dans une variété de registres parlés et écrits.
Bien que quelques études de corpus se concentrent sur la description de la variation d'une caractéristique particulière dans un seul registre, la plupart des études de corpus comparent l'utilisation d'une caractéristique dans plusieurs variétés. Cela s'explique par le fait que l'identification de l'utilisation distinctive des caractéristiques dans un registre nécessite nécessairement que le chercheur compare l'utilisation de cette caractéristique dans un registre à son utilisation dans un autre registre. Souvent, des registres très différents sont comparés, comme c'est le cas dans les comparaisons entre la parole et l'écriture (par exemple, Biber et al. 2002). D'autres fois, un " macro " registre particulier, tel que l'écriture académique, est examiné, et des comparaisons sont faites entre les disciplines académiques (par exemple, Hyland et Tse 2004) ou entre différents types de textes au sein de l'écriture académique (par exemple, la comparaison de Conrad 2017 entre les articles de recherche, les écrits d'étudiants et les rapports de praticiens en génie civil).
L'analyse multidimensionnelle a été développée avec un objectif comparatif en tête. Dans l'analyse MD, la technique statistique de l'analyse factorielle est utilisée pour analyser les distributions de fréquence de nombreuses caractéristiques linguistiques dans des corpus représentant une gamme de domaines discursifs afin de localiser celles qui cooccurrent fréquemment. Après les analyses statistiques, une analyse qualitative des fonctions des caractéristiques co-occurrentes est entreprise pour interpréter les résultats, ce qui conduit à des généralisations sur les "dimensions" de l'utilisation de la langue. L'analyse multidimensionnelle a été utilisée pour étudier de nombreux registres différents, qu'il s'agisse de textes universitaires parlés ou écrits (Biber et al. 2002 ; Gray 2015 ; Thompson et al. 2017), de registres web (Biber et Egbert 2018), de médias sociaux et de Twitter (Clarke et Grieve 2017 ; Liimatta 2019) ou de langage télévisuel (Quaglio 2009), entre autres.
Nous espérons que cette brève revue a illustré l'éventail des approches adoptées par les chercheurs. Dans la section suivante, nous présentons une étude de cas qui intègre la grammaire et le discours en examinant comment les ressources grammaticales de l'anglais sont utilisées de manière distincte dans différents domaines du discours (conversation et écriture académique), et l'effet discursif d'une telle variation.
UNE ÉTUDE PAR SONDAGE : LA LANGUE EN USAGE
L'étude suivante (adaptée de Biber et Gray 2010) compare l'utilisation de caractéristiques linguistiques associées à la complexité structurelle et à l'élaboration dans une conversation et dans un écrit académique. Cette étude illustre une approche de recherche sur la langue en usage, et souligne l'importance d'une approche comparative et la façon dont de telles comparaisons peuvent révéler des modèles de variation allant à l'encontre des intuitions et des hypothèses sur la façon dont la langue est utilisée dans un domaine particulier.
Complexité et élaboration dans la prose et la conversation universitaires
Les chercheurs affirment depuis longtemps que, par rapport à la conversation, la prose académique est structurellement élaborée et qu'elle s'appuie davantage sur les clauses subordonnées ; par exemple, Hughes (1996 : 58-64) affirme que la grammaire parlée emploie "des clauses simples et courtes, avec peu d'enchâssement élaboré", en contraste direct avec l'écriture, qui utilise "des clauses plus longues et plus complexes avec des phrases et des clauses enchâssées". En revanche, des chercheurs comme Wells (1960) ont soutenu que l'écriture académique s'appuie fortement sur des structures nominales, et les travaux de Biber (1988) ont démontré que la subordination clausale est plus courante à l'oral, tandis que l'enchâssement phrastique est plus courant à l'écrit. Cependant, malgré ces études, la croyance selon laquelle l'écriture académique est structurellement élaborée et fait un usage intensif de l'enchâssement clausal (contrairement au discours) persiste aujourd'hui, tant chez les professeurs de langues que chez les chercheurs.
La linguistique sur corpus est une méthode idéale pour étudier ces notions largement répandues sur le discours et l'écriture académique. En comparant les distributions des caractéristiques linguistiques liées à l'élaboration structurelle dans des corpus représentant les deux domaines cibles, nous pouvons voir comment les distributions relatives réelles de ces caractéristiques diffèrent entre la parole et l'écriture, et comment ces distributions sont contraires aux croyances largement répandues sur la conversation et la prose académique.
Méthode et corpus
La première étape de l'analyse consiste à identifier les caractéristiques linguistiques qui sont liées à l'élaboration structurelle. Le tableau 7.1 énumère cinq caractéristiques des clauses dépendantes "élaborées" identifiées dans des recherches antérieures. Les clauses complémentaires (finies et non finies) fonctionnent typiquement comme l'objet direct d'un verbe, mais elles sont élaborées dans le sens où elles utilisent une clause pour remplir un espace de phrase normalement rempli par un syntagme nominal. Les clauses adverbiales et les clauses relatives, quant à elles, sont élaborées dans le sens où elles sont des ajouts facultatifs à la clause principale, ajoutées afin de fournir des informations complémentaires au verbe principal ou au nom principal.
TABLEAU 7.1 Caractéristiques grammaticales associées à l'élaboration structurelle.
Caractéristique grammaticale : Exemples
- Les compléments finis : Je ne sais pas comment ils font. Je croyais que c'était terminé.
- Compléments non finis : J'aimerais avoir un de ces cahiers. Voulez-vous développer davantage ?
- Clauses adverbiales finies : Elle ne me dénoncera pas, car elle est fière d'être un gangster. Elle peut donc accuser quelqu'un d'autre si ça ne marche pas.
- Clauses relatives finies : la quantité de déchets qui entre dans cette catégorie ... Il y a trois séries de conditions dans lesquelles la culture est élevée.
- Clauses relatives non finies : Les résultats présentés dans les tableaux IV et V complètent le tableau ...
- Les facteurs contribuant à la destruction naturelle des microbes ...
A titre de comparaison, nous avons également étudié un ensemble de caractéristiques qui ne sont pas des structures "élaborées", mais qui servent plutôt à "comprimer" l'information dans des unités denses. Ces caractéristiques sont résumées dans le tableau 7.2. Bien que toutes ces caractéristiques ajoutent également des informations supplémentaires au nom principal ou à la clause principale, il s'agit de structures comprimées utilisées pour rassembler des informations dans un petit nombre de mots, comme le montre la reformulation de ces structures avec des modificateurs clausaux plus complets, par exemple :
circonstances inhabituelles circonstances qui sont inhabituelles
effet du sel l'effet causé par le sel
les élèves de la classe les élèves qui suivent la classe
TABLEAU 7.2 Caractéristiques grammaticales associées à la compression structurelle
Caractéristique grammaticale : Exemples
- Adjectif attributif (adjectif comme pré-modificateur du nom) : un grand nombre, des circonstances inhabituelles
- Nom en tant que pré-modificateur du nom : tension superficielle, purin
- Phrase nominative appositive comme post-modificateur du nom : Dans quatre cohortes (Athènes, Keio, Mayo et Florence), les investigateurs ont déclaré que ...
- Phrase prépositionnelle en tant que substantif post-modificateur :Les scores moyens de la classe ont été calculés en faisant la moyenne des scores des étudiants cibles masculins et féminins de la classe. Des expériences ont été menées pour déterminer l'effet du sel sur la croissance et le développement du paddy.
- Phrase prépositionnelle comme adverbial : D'accord, nous vous parlerons demain matin. Va-t-il au magasin ?
L'étape suivante de l'analyse consiste à analyser les distributions de ces caractéristiques dans des corpus représentant les domaines cibles. Nous avons comparé deux corpus : (1) un corpus d'écriture académique composé de 429 articles de recherche (environ 3 millions de mots) échantillonnés dans les domaines de la science/médecine, de l'éducation, des sciences sociales (psychologie) et des sciences humaines (histoire) et (2) le sous-corpus de conversation (environ 4,2 millions de mots d'anglais américain) du Longman Spoken and Written Corpus (Biber et al. 1999 : 24-35). Ces corpus ont été annotés pour les catégories grammaticales (ou 'tagués') par le tagger de Biber. Ensuite, des programmes informatiques spécialisés ont été développés pour analyser les caractéristiques associées à l'élaboration structurelle (tableau 7.1) et à la compression (tableau 7.2).
Alors que de nombreuses caractéristiques identifiées dans les tableaux 7.1 et 7.2 ont pu être identifiées automatiquement sur la base de l'annotation grammaticale, la détermination de la fonction de caractéristiques telles que les phrases prépositives (fonctionnant comme un nom post-modificateur par rapport à un adverbe) a été un processus interactif dans lequel un programme informatique a localisé tous les quatre tokens de la caractéristique, qui ont ensuite été codés à la main. Tous les éléments des tableaux 7.1 et 7.2 ont été comptés, puis normalisés à des nombres pour 1 000 mots (voir Biber et al. 1998 : 263-4) afin de permettre une comparaison directe des fréquences de ces éléments dans les deux corpus.
Résultats de l'analyse des corpus
Les perceptions communément admises selon lesquelles les écrits académiques sont plus élaborés structurellement que la conversation permettraient de prédire que les écrits académiques utiliseraient les caractéristiques grammaticales élaborées dans une plus grande mesure que la conversation. En fait, les résultats montrent que c'est le contraire qui est vrai. La figure 7.1 montre la distribution des types de clauses dépendantes courantes. Les clauses complémentaires finies et non finies et les clauses adverbiales finies sont toutes beaucoup plus répandues dans la conversation que dans les écrits universitaires. Seules les clauses relatives finies et non finies - clauses qui modifient un nom principal - sont plus fréquentes dans les écrits universitaires que dans la conversation. Dans l'ensemble, les types de clauses dépendantes sont presque deux fois plus fréquents dans la conversation que dans les écrits universitaires.
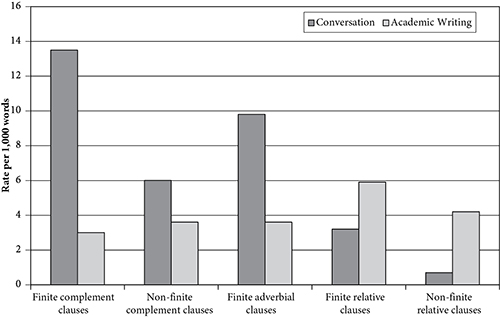
FIGURE 7.1 Types courants de clauses dépendantes (d'après Biber et Gray 2010).
En revanche, la figure 7.2 montre qu'une grande partie de l'intégration et de l'élaboration dans les écrits universitaires provient de composants phrastiques modifiant un nom principal, les quatre structures phrastiques dépendantes étant plus fréquentes dans les écrits universitaires. Les adjectifs attributifs (par exemple, renforcement différentiel, orientation théorique) et les noms en tant que modificateurs de noms (par exemple, information sur les traits, perspective du système) sont assez fréquents dans la prose universitaire par rapport à la conversation. La distribution des phrases prépositives comme post-modificateurs de nom (par exemple, une approche stratégique de la compréhension mutuelle ; un substitut pour une série de covariables non mesurées) dans la prose académique est également particulièrement importante.
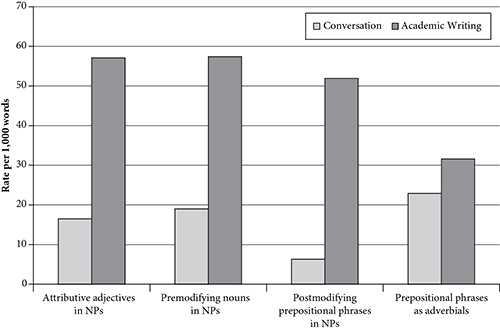
FIGURE 7.2 Types courants de phrases dépendantes (d'après Biber et Gray 2010).
Cette analyse montre que le stéréotype selon lequel les écrits universitaires sont structurellement plus complexes en termes de clauses dépendantes imbriquées n'est pas étayé par les données du corpus. Alors que la conversation utilise généralement une plus grande quantité de subordination (clauses dépendantes imbriquées) que les écrits académiques, ces derniers emploient davantage de structures imbriquées dans le syntagme nominal. Ces modèles sont évidents dans les deux extraits suivants. Le premier extrait de texte illustre l'utilisation fréquente de clauses subordonnées dans la conversation par rapport à une utilisation relativement peu fréquente de noms (et de modificateurs de noms). En revanche, le second extrait, tiré de la prose académique, illustre l'utilisation dense de modificateurs au sein du syntagme nominal, y compris les pré et post-modificateurs phrastiques et les clauses relatives. Dans les deux extraits, les caractéristiques sont marquées comme suit : noms, post-modificateurs du nom, adjectifs attributifs et clauses dépendantes en tant qu'éléments de phrase (quelques premiers mots seulement).
Extrait 1 : Extrait d'une réunion du conseil d'administration d'une organisation qui n'a pas été scriptée.
1 : Le fait est que nous n'avons besoin que d'un seul financement cette année, donc s'ils ne le font pas, VENRC devrait nous financer.
2 : C'est vrai, mais
3 : C'est vrai. Ou le département d'état. J'ai parlé à Cheryl et, et elle pensait que peut-être ils pourraient en trouver.
2 : C'est une si mauvaise année ?
Oui, oui. Ils suppriment tous les emplois sauf le sien à, tu sais, en Oklahoma. Ca devient vraiment <pas clair>.
2 : Donc, il suffit de le supprimer complètement ?
3 : Hum,... oui, le retirer complètement. Parce qu'on ne sait pas encore si elle va... je suis presque sûr. Je viens d'envoyer le, euh, <unclear> et la bio il y a deux jours à <unclear> donc peut-être que parce qu'elle n'avait pas ça, elle ne voulait pas s'engager.
1 : C'est une idée.
Extrait 2 : D'un article de recherche en biologie
Un intérêt commun de la modélisation est de faire des inférences sur l'effet des mesures longitudinales sur le temps écoulé jusqu'à l'événement, mais pas de faire des inférences sur les mesures longitudinales ou leur changement projeté dans le temps. Le modèle longitudinal est important pour tenir compte de l'erreur de mesure et définir la trajectoire longitudinale de l'individu entre les moments de mesure. Comme un modèle complexe pour les mesures longitudinales peut être trop compliqué à estimer dans le modèle conjoint, un modèle mixte linéaire paramétrique par rapport au temps est le plus souvent utilisé. Plus récemment, l'attention s'est portée sur l'assouplissement des hypothèses sur le modèle pour les données longitudinales, mais cette recherche s'est principalement concentrée sur les hypothèses de distribution des effets aléatoires et n'a pas abordé la forme de la trajectoire [...].
Malgré une longueur approximativement identique, l'utilisation dense de noms et de modificateurs nominaux (adjectifs attributifs, noms comme pré-modificateurs du nom, phrases prépositionnelles et clauses relatives comme post-modificateurs) dans l'article de Biologie est facilement évidente. En particulier, notez qu'il y a souvent plusieurs niveaux d'enchâssement dans les phrases nominales, comme dans :
inférences sur l'effet des mesures longitudinales sur le délai avant l'événement
En revanche, l'extrait de conversation s'appuie davantage sur les pronoms que sur les noms, et ne comporte qu'une seule phrase prépositionnelle modifiant un nom principal (sauf le sien). Cependant, l'extrait de conversation contient six clauses dépendantes finies.
Ces résultats de corpus et les extraits de texte ci-dessus illustrent les modèles distincts qui différencient les domaines discursifs de la conversation et de l'écriture académique en termes d'élaboration. Les écrits académiques sont complexes dans la mesure où ils utilisent l'enchâssement phrastique comme moyen d'élaboration structurelle. Bien que les mesures traditionnelles de la complexité et de l'élaboration se concentrent sur la subordination, les éléments phrastiques tels que les adjectifs attributifs, les noms en tant que pré-modificateurs du nom, les phrases nominales appositives et les phrases prépositionnelles en tant que post-modificateurs du nom sont également élaborés dans le sens où ils ajoutent des informations supplémentaires facultatives.
Cependant, ces éléments phrastiques sont condensés dans le sens où ils sont des alternatives comprimées à des modificateurs clausaux plus complets. Dans la prose universitaire, les auteurs préfèrent ces structures compactes car elles sont plus économiques et permettent au lecteur expert de traiter efficacement un grand nombre d'informations. Ainsi, si la conversation et la rédaction académique sont toutes deux complexes et élaborées, elles le sont de manière radicalement différente.
Cet exemple d'étude a montré comment les études discursives de la langue en usage basées sur un corpus peuvent mettre en évidence des modèles systématiques de variation entre les registres. En outre, elle a montré que les résultats des analyses basées sur le corpus peuvent aller à l'encontre de bon nombre de nos intuitions et/ou hypothèses sur l'utilisation de la langue dans un registre particulier.
ÉTUDIER LA STRUCTURE DE LA LANGUE AU-DELÀ DE LA PHRASE ET LES ORIENTATIONS FUTURES DE L'ANALYSE DU DISCOURS SUR CORPUS
Les approches par corpus peuvent également être utilisées pour étudier la structure du texte, ou la langue au-delà de la phrase. Biber et al. (2007), dans l'une des premières contributions de longue haleine dans ce domaine, associe l'analyse des unités fonctionnelles du discours à des méthodes linguistiques de corpus, développant ainsi un cadre complet pour l'application de l'analyse de corpus à l'analyse de la structure du texte. Biber et al. discutent de deux types d'unités de discours : celles dérivées d'une analyse descendante (par exemple, l'analyse des mouvements) et celles dérivées d'une analyse ascendante basée sur le corpus (par exemple, les 'unités de discours basées sur le vocabulaire'). Dans l'approche traditionnelle descendante, chaque texte est segmenté en "mouvements" (voir Swales 1990) en fonction de leurs fonctions dans le discours, puis analysé pour l'utilisation de caractéristiques lexicales et grammaticales. Une fois que chaque texte a été analysé, des modèles généraux peuvent être identifiés pour (a) les caractéristiques linguistiques typiques de chaque catégorie fonctionnelle de mouvements et (b) la séquence des mouvements et des fonctions à travers les textes du corpus.
Dans l'approche ascendante, les textes sont d'abord segmentés en unités de discours sur la base de critères linguistiques tels que l'utilisation changeante du vocabulaire. Chaque unité de discours est ensuite analysée pour ses caractéristiques linguistiques et classée dans des catégories linguistiquement définies (plutôt que dans des catégories fonctionnellement définies), et les modèles à travers les textes du corpus peuvent être décrits.
L'application des méthodes d'analyse de corpus à l'étude de la structure des textes présente les mêmes avantages que les analyses de corpus de la langue en usage. Bien que chaque unité discursive individuelle soit d'abord analysée, l'objectif final est d'identifier des modèles à travers les textes du corpus afin de révéler des observations généralisables sur le registre cible. Étant donné que de grandes quantités de données peuvent à nouveau être analysées en termes quantitatifs et qualitatifs, il est possible d'effectuer des comparaisons entre les registres ou les genres. Cela contraste avec les études traditionnelles sur la structure des textes qui se sont concentrées sur des descriptions détaillées, principalement qualitatives, d'un seul texte ou d'un très petit nombre de textes d'un seul genre. Biber et al. (2007) ont ainsi montré qu'il est utile d'utiliser l'analyse de corpus pour analyser la structure des textes, en intégrant des analyses quantitatives et généralisables à des descriptions qualitatives. Si cette méthodologie n'avait pas encore été largement appliquée lors de la publication de la première édition de cet ouvrage, les analyses de corpus à grande échelle de ce type sont devenues plus courantes aujourd'hui (par exemple, Kanoksilapatham 2007 sur les articles de biochimie ; Cotos, Huffman et Link 2017 sur les articles de recherche).
Comme les analyses de la structure des textes basées sur les corpus ont augmenté, il en est de même pour les recherches qui ont fait le pont entre la langue en usage et la langue au-delà des perspectives de la phrase pour offrir des descriptions linguistiques détaillées des unités de discours structurelles comme les mouvements ou les unités de discours basées sur le vocabulaire. Par exemple, Cortes (2013) et Omidian et al. (2018) considèrent la cooccurrence des faisceaux lexicaux et des mouvements rhétoriques pour identifier les phraséologies clés associées à la structure du discours. Motivés par les préoccupations liées à l'anglais à des fins académiques, les appels à la recherche qui aident à relier les principales ressources grammaticales aux mouvements rhétoriques pour informer l'enseignement de l'écriture de recherche se sont multipliés. Des études telles que Tankó (2017, sur les résumés d'articles de recherche) et Gray, Cotos et Smith (2020, sur les articles de recherche IMRD) fournissent des descriptions détaillées des réalisations linguistiques des mouvements. Nous espérons que ce type de travaux continuera à se développer, en utilisant les forces de l'analyse de corpus pour décrire le discours et ses caractéristiques linguistiques et rhétoriques.