
Les systèmes de recommandation visent à faciliter la recherche et la prise de décision des utilisateurs lorsqu'ils sont confrontés à un grand nombre d'options disponibles, comme l'achat de produits en ligne ou la sélection de morceaux de musique à écouter. Un large éventail de modèles et d'algorithmes d'apprentissage automatique a été développé pour prédire l'évaluation par les utilisateurs d'articles non vus et pour recommander des articles qui correspondent le mieux à leurs intérêts. Toutefois, il a été démontré que l'optimisation du système en termes de précision de l'algorithme ne se traduit pas toujours par un niveau élevé de satisfaction de l'utilisateur. Il est donc nécessaire d'adopter une approche plus centrée sur l'utilisateur pour développer des systèmes de recommandation qui tiennent mieux compte des objectifs réels des utilisateurs, du contexte actuel et de leurs exigences cognitives. Dans ce chapitre, nous examinons un certain nombre de techniques et d'aspects de la conception qui peuvent contribuer à accroître la transparence, la compréhension de l'utilisateur et le contrôle interactif des systèmes de recommandation. En outre, nous présentons des méthodes d'évaluation des systèmes du point de vue de l'utilisateur et indiquons des pistes de recherche pour l'avenir.
Mots-clés : Systèmes de recommandation, visualisation, recommandation interactive, explications, évaluation,
2.1 Introduction
Les systèmes de recommandation (SR) visent à aider les utilisateurs dans leur processus de recherche et de prise de décision lorsqu'ils interagissent avec des systèmes en ligne dans divers domaines d'application, tels que le commerce électronique, la diffusion de médias en continu ou les médias sociaux. En raison du très grand nombre d'articles généralement disponibles sur ces plateformes, les SR sont devenus des outils très répandus, voire indispensables, pour contrer le problème de surcharge de choix qui résulte souvent de ces vastes ensembles d'options. Contrairement à d'autres types de systèmes basés sur l'IA, les SR s'attaquent à la tâche du choix préférentiel où il n'y a pas un seul résultat correct mais un classement des options qui peut correspondre aux préférences de l'utilisateur à différents degrés et qui est, par conséquent, principalement personnalisé.
Par le passé, le développement des SR a été largement guidé par une perspective algorithmique, axée sur l'efficacité et la précision des algorithmes, définies comme la prédiction correcte des choix probables de l'utilisateur sur la base des signaux collectés à partir des interactions passées de l'utilisateur avec le système [51]. Ces signaux peuvent provenir des interactions de l'utilisateur cible avec les articles et leurs caractéristiques dans les méthodes de filtrage basées sur le contenu, tandis que dans l'approche populaire du filtrage collaboratif, les données obtenues auprès de l'utilisateur cible et d'autres utilisateurs similaires sont exploitées pour générer des recommandations. Les signaux exploités peuvent consister en un retour d'information explicite de la part de l'utilisateur, comme les évaluations soumises pour les produits choisis, ou en des données collectées implicitement, comme les clics sur les articles, la durée de visualisation ou d'autres données d'interaction, à partir desquelles un modèle d'utilisateur personnalisé est construit. Dans la perspective algorithmique dominante, les utilisateurs sont généralement traités comme des sources de signaux de préférence. Le contenu du modèle d'utilisateur stocké et le fonctionnement du processus de recommandation ne peuvent être ni inspectés ni contrôlés par l'utilisateur. La plupart des SR peuvent donc être décrits comme des boîtes noires qui empêchent les utilisateurs de comprendre quelles données sont utilisées et comment les résultats sont créés. En outre, l'apprentissage des algorithmes de RS est généralement basé sur des ensembles de données historiques de signaux de préférence dans le but de prédire avec précision les réactions de l'utilisateur qui se sont produites dans le passé, sans tenir compte des objectifs actuels de l'utilisateur, qui peuvent dépendre du contexte et être à court terme [40]. En conséquence, les utilisateurs peuvent éprouver des difficultés à évaluer la pertinence des recommandations, se sentir dominés par le système ou se méfier complètement du SR [33].
La perspective purement algorithmique, qui met l'accent sur la précision, est de plus en plus critiquée comme étant insuffisante pour atteindre les critères de qualité centrés sur l'utilisateur, tels que la qualité perçue des recommandations, la diversité ou la fiabilité des recommandations [50]. L'orientation vers un développement et une évaluation des SR plus centrés sur l'utilisateur a donné lieu, ces dernières années, à un nombre considérable d'études visant à rendre les SR contrôlables par l'utilisateur et plus transparents. L'une des conséquences de ce virage centré sur l'utilisateur est que les aspects de l'interface utilisateur des SR, par exemple la présentation visuelle des éléments, ont fait l'objet d'une plus grande attention. Par ailleurs, les SR ne permettent généralement pas à l'utilisateur d'influencer le processus de recommandation et les recommandations qui en résultent, qui sont généralement présentées sous forme de "tout ou rien". Pour accroître le contrôle de l'utilisateur, diverses techniques interactives ont été proposées pour transformer le processus de recommandation en un dialogue multitour entre l'utilisateur et le système [46]. L'interaction avec un SR peut porter sur divers aspects du processus, tels que la spécification interactive de ses préférences [59], la sélection de méthodes de recommandation appropriées ou l'influence sur leur fonctionnement [20], [27], et la critique, c'est-à-dire la modification des attributs d'un article pour recevoir des recommandations actualisées [18].
Pour ajouter au manque de contrôle, les SR conventionnels ne sont généralement pas transparents et leurs résultats sont difficiles à comprendre en raison de leurs caractéristiques de boîte noire. La plupart du temps, les utilisateurs ne sont pas en mesure de comprendre pourquoi un certain article est recommandé et s'il correspond réellement à leurs besoins et à leurs préférences. L'un des moyens de remédier au manque de transparence consiste à fournir des explications. Diverses méthodes d'explication ont été proposées ces dernières années, visant à promouvoir la transparence et l'intelligibilité du SR [81], facteurs qui peuvent également accroître la confiance dans le système [69]. Au-delà de l'explication des recommandations, le fait de fournir aux utilisateurs des moyens de contrôle interactif peut également accroître la transparence et la compréhension de l'utilisateur. Les techniques qui permettent aux utilisateurs d'explorer de manière interactive les options disponibles, de modifier leur modèle d'utilisateur ou d'influencer l'algorithme de recommandation et ses données d'entrée peuvent toutes favoriser la compréhension. Ces techniques peuvent aider à répondre à des questions hypothétiques et à acquérir une meilleure compréhension grâce à l'exploration contrefactuelle [90]. Toutefois, ces techniques sont encore très rarement utilisées dans des applications réelles.
Le présent chapitre ne vise pas à fournir un compte rendu complet du grand nombre de techniques de recommandation et des aspects liés à l'IHM. Pour un traitement plus complet, le lecteur est invité à consulter des sources exhaustives telles que le Recommender Systems Handbook de Ricci et al [73].
Dans ce chapitre, nous donnons un aperçu des aspects de la conception des SR qui sont pertinents d'un point de vue centré sur l'utilisateur, sans viser une couverture complète de la vaste gamme de techniques de recommandation et de leurs implications pour les utilisateurs. Le reste du chapitre est organisé comme suit : Dans la section suivante, nous abordons la présentation et la visualisation des recommandations. Ensuite, nous présentons une série de méthodes interactives visant à accroître le contrôle de l'utilisateur. Nous commençons cette section par une discussion sur les méthodes permettant d'obtenir les préférences de l'utilisateur, suivie d'une vue d'ensemble des méthodes permettant de contrôler le processus de recommandation. En outre, les recommandeurs conversationnels sont présentés comme une technique de recommandation interactive de plus en plus importante. Dans la section suivante, nous passons brièvement en revue les méthodes d'explication de la RS, suivies d'une section sur les mesures et les méthodes d'évaluation de la RS d'un point de vue centré sur l'utilisateur. Enfin, nous esquissons quelques pistes de recherche pour l'avenir.
2.2 Présentation et visualisation des recommandations
De plus en plus d'études montrent que l'information et le style de présentation des recommandations peuvent avoir une grande influence sur les choix de l'utilisateur. Dans le cas le plus simple, les recommandations sont présentées sous la forme d'une courte liste textuelle ne contenant que des informations descriptives très limitées. Pourtant, la disponibilité d'informations plus détaillées sur les produits semble influencer positivement la perception du SR par les utilisateurs et peut renforcer leur confiance dans le système [79].
Beel et Dixon [9] ont comparé sept variantes d'un panneau de recommandation, en faisant varier la visibilité des vignettes, des résumés et des informations complémentaires, ce qui constitue l'un des rares travaux portant sur les questions de présentation des éléments recommandés. Ils ont constaté que de petites modifications peuvent déjà avoir un effet important sur le taux de clics, et que la meilleure performance était obtenue avec la version où des informations supplémentaires pouvaient être obtenues au survol de la souris. Dans le cadre de la recherche et de la recommandation de documents, de courts extraits ou résumés des documents sources sont souvent présentés pour permettre aux utilisateurs de prédire l'utilité d'un élément dans le cadre de leur recherche actuelle [19]. De même, des éléments non textuels, tels que des images d'affiches de films, peuvent aider les utilisateurs à prédire la qualité des éléments recommandés [57]. Les informations explicatives liées aux évaluations ou aux critiques d'autres utilisateurs ont également été jugées utiles pour évaluer la valeur des recommandations (voir la section 2.4 ainsi que le chapitre 6 (Explications et contrôle de l'utilisateur dans les systèmes de recommandation) du présent ouvrage).
2.2.1 Listes de recommandations
Les éléments recommandés sont traditionnellement présentés sous forme de listes, à la verticale ou à l'horizontale. Jugovac et Jannach [46] examinent divers aspects de la conception, tels que l'ordre des éléments, l'étiquette de la liste, la longueur de la liste et la description des éléments, qui peuvent influencer la perception et l'acceptation des recommandations par les utilisateurs. La position d'un élément est l'un des principaux facteurs prédictifs de la probabilité que l'utilisateur clique sur cet élément. Ce biais de position [7] a été démontré depuis longtemps pour les pages de résultats de recherche d'informations, mais il est également présent dans les listes de recommandations [34]. Habituellement, les éléments sont positionnés en fonction de leur score de pertinence prédit, l'élément ayant le score le plus élevé étant placé au début de la liste. Toutefois, la prise en compte de facteurs supplémentaires tels que l'attrait, la diversité ou la nouveauté lors de l'établissement de l'ordre final peut augmenter le taux de clics et conduire à une plus grande satisfaction de l'utilisateur [85], [92].
La longueur de la liste est également un facteur essentiel. Plusieurs études portant sur des choix physiques ont montré qu'une augmentation excessive du nombre de produits disponibles peut entraîner une surcharge de choix, c'est-à-dire une augmentation du temps de décision et une diminution de la satisfaction à l'égard du produit finalement choisi, voire empêcher les utilisateurs de prendre une décision [37]. Toutefois, comme Scheibehenne, Greifeneder et Todd [77] le montrent dans leur méta-analyse, l'apparition d'une surcharge de choix peut dépendre de la connaissance du domaine par les utilisateurs et de la spécificité de leurs objectifs, ainsi que de la présence d'éléments dominants dans l'ensemble de choix. Bollen et al [10] ont comparé des listes de recommandation de 5 et 20 éléments. Si la liste la plus longue augmentait l'attrait des recommandations, elle augmentait également la difficulté du choix ; cependant, ces effets opposés semblaient se neutraliser, ce qui se traduisait par un niveau de satisfaction identique à celui de la liste la plus courte. En outre, les auteurs ont constaté qu'une plus grande diversité des éléments contenus dans la liste augmentait l'attrait perçu de la liste. Ils supposent qu'il pourrait y avoir une relation en forme de U entre la longueur de la liste et la satisfaction de l'utilisateur, le nombre optimal se situant dans la moyenne. En général, toutefois, le juste équilibre entre un ensemble de choix trop restreint et une surcharge de choix peut dépendre d'un certain nombre de facteurs, notamment le domaine du produit, l'appareil utilisé et les caractéristiques psychologiques de l'utilisateur, par exemple s'il a tendance à prendre des décisions basées sur l'intuition plutôt que sur la raison.
2.2.2 Présentation des listes et listes multiples
Il a souvent été avancé que la présentation typique sous forme de liste classée n'est pas optimale à plusieurs égards, par exemple parce qu'elle peut intensifier le biais de position. Chen et Tsoi [17] ont comparé différentes présentations et ont constaté que dans les présentations en liste et en grille, les utilisateurs cliquaient plus souvent sur les recommandations les plus importantes, alors que dans une présentation circulaire, les éléments moins bien classés étaient également fréquemment cliqués. Les listes simples présentent également l'inconvénient de ne pas transmettre une organisation significative des éléments au-delà de leur classement. Le regroupement des éléments en fonction de facteurs tels que la similarité sémantique ou la proximité avec les préférences de l'utilisateur et leur présentation dans des listes distinctes peuvent faciliter la recherche et la compréhension des recommandations par l'utilisateur. Dans une étude de suivi oculaire, Chen et Pu [16] ont constaté que dans une présentation groupée, l'attention était répartie plus équitablement entre les éléments et que les utilisateurs faisaient plus souvent un choix.
Ces dernières années, les interfaces de type carrousel sont devenues un moyen populaire. Par exemple, Netflix et Amazon affichent plusieurs listes de recommandations l'une en dessous de l'autre, chacune contenant des articles ayant des caractéristiques communes. Les utilisateurs peuvent ainsi explorer une gamme plus diversifiée de recommandations et trouver des articles qui correspondent mieux à leurs besoins actuels [39]. Il a également été constaté que les carrousels réduisent le nombre d'étapes d'interaction [71]. L'organisation sémantique est généralement transmise par l'ajout d'une étiquette à chaque liste. Pour le regroupement, différents concepts peuvent être utilisés, tels que les caractéristiques des articles (par exemple, les genres de films), la popularité ou les préférences de l'utilisateur. La définition d'un ensemble approprié de catégories est un défi important en matière de conception [21]. En outre, les carrousels augmentent la complexité du problème de classement, car il faut tenir compte non seulement du classement à l'intérieur d'une liste, mais aussi du classement vertical des listes.
2.2.3 Visualisation des recommandations
Les méthodes graphiques offrent un certain nombre d'avantages qui peuvent aider à surmonter les limites d'une présentation des recommandations sous forme de liste. Par exemple, elles permettent de présenter plus efficacement de grands ensembles d'éléments et de mettre en évidence les relations entre les éléments. Diverses techniques de visualisation de l'information ont été adoptées pour les RS, qui peuvent être classées selon les dimensions suivantes :
- Structure visuelle, par exemple séquence, ensemble ou grappe, graphique, disposition multidimensionnelle, carte
- Portée, c'est-à-dire uniquement les éléments recommandés, des parties de l'espace des éléments, l'ensemble de l'espace des éléments
- Interactivité, par exemple, classement, pondération, filtrage.
Les diagrammes de Venn sont des exemples qui permettent aux utilisateurs d'inspecter le chevauchement des ensembles d'éléments recommandés filtrés selon différents critères [65]. Ainsi, les utilisateurs peuvent explorer les éléments qui correspondent entièrement ou partiellement à leurs paramètres de filtrage, ce qui s'est avéré plus attrayant que les listes et a amélioré l'expérience de l'utilisateur. Les diagrammes de Venn ont également été utilisés pour expliquer la similarité entre les utilisateurs dans les recommandations sociales [83]. Dans ce domaine, les graphiques présentés sous forme de diagrammes nœuds-liens constituent une autre méthode de visualisation utile. Par exemple, Gretarsson et al [25] utilisent un graphique multicouche dans lequel les utilisateurs, leurs préférences, leurs pairs sociaux et les recommandations sont affichés sous forme de nœuds. Les utilisateurs peuvent manipuler la position de ces nœuds, influençant ainsi leur pertinence pour les recommandations. Dans une étude sur les utilisateurs, les auteurs ont constaté que les utilisateurs avaient un niveau de contrôle plus élevé et comprenaient mieux le processus de filtrage collaboratif sous-jacent. Petridis et al [68] ont proposé le système de recommandation musicale TastePaths, qui présente les artistes sous forme de nœuds dans un graphe. Ils ont constaté que le système peut éduquer les utilisateurs sur les relations entre les artistes, les aidant ainsi à découvrir des contenus dont ils n'avaient pas connaissance.
Les nuages de points combinent une présentation bidimensionnelle des éléments avec un filtrage interactif. Dans MusiCube [76], les utilisateurs peuvent sélectionner des caractéristiques musicales (par exemple, le tempo, la texture acoustique) pour modifier les axes d'un nuage de points de chansons, où les recommandations sont mises en évidence par des couleurs. Scatter Viz [82] est un RS social qui recommande des universitaires sur la base d'un profil de recherche. Dans le cadre d'une étude sur les utilisateurs, l'interface proposée s'est révélée plus performante qu'une présentation sous forme de liste sur plusieurs aspects centrés sur l'utilisateur, tels que la confiance, le soutien et l'intention de réutilisation.
Les cartes se sont avérées particulièrement utiles pour fournir une vue d'ensemble de vastes ensembles d'éléments tout en transmettant des informations sur la similarité des éléments, c'est-à-dire que les éléments similaires sont généralement plus proches les uns des autres. Dans les SR, les cartes sont le plus souvent des projections générées automatiquement de dimensions latentes, par exemple dérivées de données d'évaluation collaborative, dans un espace en 2D ou en 3D. Cela peut fournir un contexte global pour les recommandations en les positionnant par rapport aux autres éléments disponibles, ce qui favorise l'exploration et la compréhension de l'utilisateur. Par exemple, dans TVLand [22], des groupes d'émissions télévisées sont affichés sous forme de carte avec une superposition de cartes thermiques pour indiquer les recommandations. Dans MoodPlay [5], les chemins affichés sur la carte montrent également les interactions précédentes ou futures suggérées par l'utilisateur.
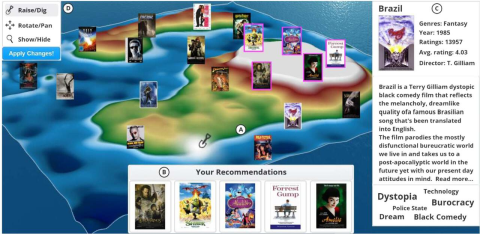
Figure 2.1 Exemple de visualisation de l'espace des éléments : (A) Carte avec des échantillons de films représentatifs illustrant les différentes zones. Les élévations représentent les préférences de l'utilisateur actif. Les recommandations actuelles sont représentées par un cadre coloré. (B) Panneau de recommandations supplémentaires. (C) Détails du film sélectionné. (D) Palette d'outils permettant de modifier la vue et de remodeler le paysage, ce qui entraîne un recalcul immédiat des recommandations [53].
Cependant, seuls quelques travaux ont abordé la manipulation interactive des préférences dans les cartes. MovieLandscape est une carte en 3D qui permet de modifier les préférences grâce à l'"ingénierie paysagère" [53]. Les utilisateurs peuvent élever l'altitude des zones qui les intéressent, tandis que le fait de "creuser" indique un intérêt moindre pour les éléments situés dans cette zone (figure 2.1). Par conséquent, les utilisateurs peuvent exprimer leurs préférences pour une série d'éléments, au lieu d'être limités à l'évaluation d'un seul élément, comme c'est généralement le cas. Dans une étude sur les utilisateurs, les auteurs ont constaté que la carte les aidait à comprendre leur profil d'utilisateur par rapport au reste de l'espace des éléments et à prendre conscience de l'ensemble des options de choix. Les cartes arborescentes sont une forme plus abstraite de cartes, qui ont été utilisées pour afficher des groupes d'articles dans des zones rectangulaires dont la taille est fonction du nombre d'articles dans une catégorie [74]. Ces cartes ont également été complétées par des moyens interactifs permettant de modifier les préférences [54].
2.3 Élicitation des préférences et contrôle interactif
Le SR conventionnel calcule des recommandations et les présente en une seule fois sans que les utilisateurs puissent influencer le processus. Cependant, les utilisateurs souhaitent souvent avoir plus de contrôle en temps réel sur le processus afin de mieux adapter les recommandations à leurs besoins situationnels. Il a été démontré qu'un plus grand sentiment de contrôle est fortement lié à l'expérience de l'utilisateur et contribue considérablement à sa satisfaction [46], [50]. Plus récemment, plusieurs approches interactives de la recommandation ont été proposées pour traiter différents aspects ou phases du processus. Parmi ces aspects, on peut citer les méthodes permettant d'obtenir les préférences des utilisateurs, d'évaluer l'influence des différentes sources de données ou des algorithmes, ou de critiquer les éléments recommandés. En outre, les techniques conversationnelles, qui utilisent des interfaces graphiques ou des dialogues en langage naturel, ont récemment fait l'objet d'une attention considérable.
2.3.1 Évaluation et comparaison des articles
Pour fournir des recommandations personnalisées, les SR doivent être en mesure de connaître les préférences des utilisateurs. Dans de nombreux SR, y compris des exemples commerciaux réussis tels que ceux utilisés par Amazon et Netflix [23], [56], le seul moyen pour les utilisateurs d'informer explicitement le SR de leurs préférences est de noter les articles qu'ils ont consommés ou achetés, une action qui ne prend généralement effet qu'au cours des sessions ultérieures. Dans le cadre de la recherche expérimentale, les évaluations d'un ensemble d'articles sont souvent collectées avant d'utiliser le SR pour établir un modèle d'utilisateur, mais cette approche n'est pas pratique dans les applications du monde réel. Les évaluations sont généralement fournies sous la forme d'un retour unaire (par exemple, "j'aime"), binaire (par exemple, "pouce en l'air" ou "pouce en bas") ou ordinal (par exemple, échelle de 1 à 5 étoiles) [41].
Idéalement, les méthodes d'obtention des préférences devraient inciter les utilisateurs à répondre, les aider à formuler leurs préférences avec précision et sincérité, gérer les conflits et leur permettre de réviser ce qu'ils ont dit au système lors des sessions précédentes [69]. Il est souvent difficile d'atteindre ces objectifs avec des évaluations post-consommation portant sur un seul élément. Les exemples de YouTube et de Netflix montrent que les différents types d'évaluation ont des forces et des faiblesses différentes.1 Par exemple, lorsque les évaluations à 5 étoiles étaient encore utilisées sur ces plateformes, les utilisateurs fournissaient presque exclusivement des évaluations extrêmes, ce qui se traduisait par des distributions d'évaluation bimodales. C'est ce qui a conduit les deux fournisseurs de RS, il y a plusieurs années, à passer aux évaluations binaires. Récemment, toutefois, une tendance inverse a été observée, par exemple sur Netflix, où le "super like" a été introduit pour obtenir des données de préférence plus riches. Le retour d'information basé sur l'évaluation a également fait l'objet de nombreuses expériences, montrant que les évaluations peuvent être bruyantes, inexactes ou instables dans le temps (Amatriain et al. [4] ; Jones, Brun et Boyer [45]). En outre, les différents types de retour d'information diffèrent en termes d'effort d'utilisation et de charge cognitive [62]. Pour ces raisons, de nombreux SRM du monde réel s'appuient sur un retour d'information implicite de l'utilisateur, tel que les pages consultées, la durée des visites ou les achats [41]. Étant donné que ces données sont souvent en corrélation avec le retour d'information explicite et qu'elles sont en même temps beaucoup plus faciles à obtenir du point de vue du fournisseur [64], le retour d'information implicite est aujourd'hui largement adopté pour générer des recommandations personnalisées [46]. Dans ce cas, cependant, les utilisateurs ont encore moins de contrôle sur les recommandations et l'interprétation des résultats devient plus difficile.
Le retour d'information implicite ou explicite de l'utilisateur se réfère principalement à des articles uniques et complets. Seuls quelques auteurs ont étudié des approches dans lesquelles les utilisateurs peuvent exprimer leurs préférences à l'égard d'un certain nombre d'attributs d'articles, par exemple sur la base de métadonnées prédéfinies [2]. Cette approche est particulièrement utile dans les domaines de produits complexes, où certaines caractéristiques d'un produit revêtent une importance particulière pour l'utilisateur, mais elle est également exigeante sur le plan cognitif et accroît la rareté des données. En général, les évaluations en valeur absolue se sont révélées cognitivement exigeantes et peu fiables. Une autre solution consiste à exprimer les préférences des articles de manière relative, en s'inspirant du comportement des consommateurs dans des environnements physiques, où les décisions d'achat sont généralement prises après avoir comparé les produits. En conséquence, l'élicitation des préférences basée sur la comparaison, qui est souvent utilisée dans la recherche en marketing, s'est également avérée faciliter les évaluations et augmenter la qualité des recommandations [75]. Jones, Brun et Boyer [45] ont été les premiers à présenter aux utilisateurs de RS des comparaisons d'articles par paire au lieu de leur demander d'évaluer les articles un par un (figure 2.3, à gauche). Dans une étude sur les utilisateurs, ils ont montré que la prise de décision pouvait ainsi être facilitée et que les préférences devenaient plus stables. Rokach et Kisilevich [75] ont proposé une méthode similaire spécifiquement pour les approches modernes de filtrage collaboratif. L'approche tient compte des interdépendances entre les éléments qui sont autrement ignorées et peut donc favoriser une modélisation plus précise des préférences de l'utilisateur.

Figure 2.2 Exemple d'élicitation de préférences basée sur la comparaison, où les utilisateurs se voient présenter des ensembles d'éléments échantillonnés à partir d'un espace factoriel latent sous-jacent [59].
Quelques auteurs ont proposé d'échantillonner les éléments directement à partir d'un espace de facteurs latents tel qu'il est dérivé dans les algorithmes de filtrage collaboratif de pointe tels que la factorisation de la matrice. Loepp, Hussein et Ziegler [59] sélectionnent les éléments représentatifs facteur par facteur, ce qui permet aux utilisateurs de choisir entre des groupes d'éléments en plusieurs étapes de dialogue, chaque étape correspondant à un facteur du modèle sous-jacent (figure 2.2). Dans une étude sur les utilisateurs, les auteurs ont constaté que cette approche constituait un bon compromis entre les mécanismes de filtrage manuel et un traitement largement automatisé des évaluations d'éléments. L'approche proposée par Graus et Willemsen [24] confronte les utilisateurs, en plusieurs étapes, à des ensembles d'éléments recommandés, en leur demandant de choisir un élément à la fois. La diversité des ensembles d'éléments est maximisée afin de présenter aux utilisateurs l'ensemble des choix possibles et d'apprendre autant que possible de leurs décisions. Plusieurs expériences ont montré que les utilisateurs préfèrent les comparaisons à l'évaluation des éléments et qu'ils les trouvent plus faciles pour fournir un retour d'information sur des éléments provenant de différentes parties de l'espace des éléments. En outre, les comparaisons se sont révélées particulièrement utiles dans les situations de démarrage à froid, où il peut être difficile de motiver les utilisateurs à évaluer un nombre suffisamment important d'éléments, ce qui est nécessaire pour générer des recommandations significatives.
2.3.2 Contrôle du processus de recommandation et des résultats
Certains travaux récents visent plus généralement à permettre à l'utilisateur de contrôler les méthodes de recommandation et les composantes connexes de la RS, ou à produire des résultats avec lesquels l'utilisateur peut interagir directement. Bien qu'elles soient encore rares dans les applications réelles, les méthodes proposées dans les milieux universitaires sont relativement nombreuses. Dans les formes les plus simples, des gadgets interactifs sont fournis pour permettre aux utilisateurs de modifier les paramètres de l'algorithme [27] ou de choisir parmi différents algorithmes [20]. Dans les systèmes hybrides, qui combinent plusieurs algorithmes pour bénéficier de leurs avantages individuels, l'influence de chaque algorithme peut être manipulée. Le RS musical TasteWeights proposé par Bostandjiev, O'Donovan et Höllerer [11] en est un exemple frappant. Comme le montre la figure 2.3, des curseurs permettent aux utilisateurs de contrôler l'influence individuelle des artistes préférés ainsi que des sources de données associées aux différentes méthodes de recommandation. Les liens entre ces entités et les recommandations qui en résultent sont mis en évidence graphiquement. Une expérience utilisateur a montré que ce processus de génération de recommandations était perçu comme plus transparent et que la visualisation aidait à comprendre le comportement du système. En outre, les capacités d'interaction supplémentaires ont permis d'améliorer considérablement la qualité perçue des recommandations et la satisfaction générale. Des résultats similaires ont été obtenus avec plusieurs systèmes successeurs de TasteWeights (voir, par exemple, Bostandjiev, O'Donovan et Höllerer [12]) ainsi qu'avec d'autres systèmes (voir, par exemple, Cardoso et al. [14]).
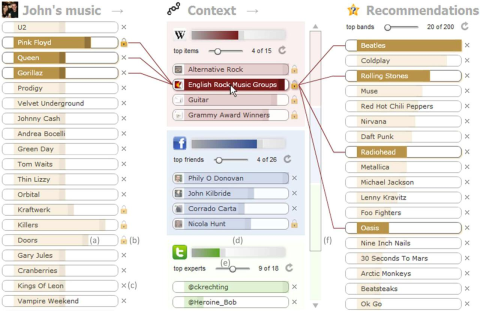
Figure 2.3 Capture d'écran du système TasteWeights : Dans la partie gauche, les utilisateurs peuvent modifier le poids des artistes dans leur profil. En outre, ils peuvent ajuster l'influence des différentes sources dans la colonne centrale et observer immédiatement les effets sur les recommandations, qui sont affichées dans la partie droite ([11], utilisé avec l'autorisation de l'ACM, transmis par le Copyright Clearance Center, Inc.)
D'autres travaux s'attachent à donner aux utilisateurs un contrôle sur les résultats du système. La critique des exemples est l'une des techniques les plus en vue [18]. Elle permet aux utilisateurs de modifier itérativement les valeurs des attributs des éléments recommandés (les exemples), soit en sélectionnant une valeur différente, soit en indiquant le sens du changement souhaité (par exemple, plus ou moins élevé). L'application des critiques entraîne une mise à jour immédiate des recommandations. Ainsi, les utilisateurs peuvent partir d'un article recommandé qui correspond déjà à leurs besoins (dans une certaine mesure), mais indiquer ensuite, par exemple, une préférence pour des produits moins chers, des produits d'un autre fabricant ou d'une couleur différente. Cela repose sur l'hypothèse qu'il est plus facile de dire au système ce qui ne va pas dans les résultats que de formuler des exigences précises à l'avance. En l'absence d'indices cognitifs, il s'agit d'un problème particulier lorsque la connaissance du domaine est insuffisante [88]. Alors que les premières variantes, telles que le système FindMe de Burke et al. [13], ne permettaient aux utilisateurs de critiquer qu'une seule propriété d'article à la fois, Reilly et al. [72] ont introduit les critiques composées comme moyen de fournir simultanément un retour d'information concernant plusieurs propriétés d'article.
La critique d'exemples est généralement mise en œuvre sur la base de métadonnées prédéfinies, dont l'obtention peut être coûteuse. Toutefois, il ne s'agit pas nécessairement d'une condition préalable. Par exemple, les balises générées par la communauté d'utilisateurs peuvent également être exploitées pour mettre en œuvre un mécanisme de critique [87]. En outre, Xie et al [88] ont proposé une structure basée sur un graphe pour représenter les sessions de critique passées, ce qui leur permet de suggérer des éléments compatibles avec la critique de l'utilisateur et similaires aux éléments que d'autres utilisateurs ont précédemment acceptés dans une situation similaire. Dans une étude de simulation basée sur des ensembles de données réelles, cela a permis de réduire le nombre de tours dans le processus de critique. Loepp et al [58] ont combiné cette forme de critique basée sur le contenu avec le filtrage collaboratif et ont constaté qu'avec leur méthode TagMF, les utilisateurs évaluent les recommandations de manière nettement meilleure dans un certain nombre de dimensions que dans le cas d'une critique basée exclusivement sur les étiquettes. En outre, ils ont fourni un mécanisme permettant aux utilisateurs d'ajuster les résultats du système en sélectionnant des balises et en appliquant des poids individuels à chaque balise sélectionnée. L'utilisation de curseurs pour ajuster les recommandations a également retenu l'attention d'autres auteurs, en particulier dans le domaine de la musique. Par exemple, Jin et al [43] ont proposé une interface similaire au système TasteWeights, mais avec des curseurs qui permettent aux utilisateurs d'ajuster le poids des artistes ou des genres sélectionnés. Liang et Willemsen [55] utilisent des caractéristiques spécifiques telles que l'énergie et la valence des chansons pour améliorer le contrôle de l'utilisateur. En outre, ils utilisent une visualisation en courbes de niveau pour favoriser l'exploration de nouveaux genres. En général, plusieurs auteurs ont suggéré d'utiliser des techniques de visualisation de l'information pour présenter les résultats du système de manière à permettre aux utilisateurs de manipuler la manière dont les recommandations sont générées. Ces travaux ont montré leur potentiel dans un certain nombre d'études d'utilisateurs, mais ils sont souvent trop complexes pour être appliqués à grande échelle. Pour une vue d'ensemble, nous renvoyons à la section 2.2.3 et à l'étude de He, Parra et Verbert [28].
Enfin, il existe quelques approches qui visent à accroître l'interactivité d'autres composantes du RS. Par exemple, des quiz interactifs et des mécanismes de gamification ont été proposés pour étendre le modèle de l'utilisateur afin de capturer la personnalité de l'utilisateur [35], [80]. Les systèmes de Baltrunas et al [8] et de Najafian, Wörndl et Braunhofer [61] sont quelques-unes des rares exceptions où les utilisateurs peuvent décider quelles informations contextuelles sont prises en compte, même si le maintien d'un modèle contextuel est de plus en plus considéré comme essentiel pour le succès des SR [1].
2.3.3 Approches de recommandation conversationnelle
En raison des progrès récents dans le traitement du langage naturel basé sur des techniques d'apprentissage profond, la conversation en langage naturel est devenue un autre moyen populaire d'interagir avec les SR. Les systèmes de recommandation conversationnels (CRS) tentent de détecter les intentions des utilisateurs dans leurs énoncés textuels ou oraux, par exemple en exprimant une préférence ou en demandant une recommandation. En outre, les systèmes gardent une trace de l'état de la conversation. Par exemple, un graphe de dialogue qui décrit des états de dialogue (prédéfinis) et les transitions entre ces états peut être utilisé pour "remplir des créneaux", c'est-à-dire que le système pose des questions sur les préférences de l'utilisateur en ce qui concerne un certain ensemble de caractéristiques d'éléments. Par ailleurs, les moteurs de dialogue tels que celui utilisé dans le Dialogflow de Google utilisent des techniques d'apprentissage automatique pour modéliser un ensemble d'intentions de l'utilisateur, détecter celle qui est la plus probable et, par la suite, poser une question ou afficher une recommandation [38]. Pour un aperçu plus détaillé des algorithmes utilisés dans les SRC, nous nous référons à l'étude de Jannach et al [38].
Bien que les SRC puissent utiliser différentes modalités, y compris la parole, la forme dominante d'interaction est simplement textuelle. Seuls quelques auteurs ont étudié la manière d'aider les utilisateurs à répondre aux questions d'un chatbot. Iovine et al [36] présentent le cadre ConveRSE et ont constaté que les utilisateurs étaient moins efficaces dans une interface purement textuelle, en particulier dans les situations où une saisie précise était nécessaire. Ils concluent que lorsque les utilisateurs doivent choisir parmi un ensemble d'options, d'autres stratégies d'interaction doivent être mises à leur disposition. En conséquence, Jin et al [42] ont également intégré des boutons dans l'interface d'un chatbot, mais spécifiquement pour critiquer les recommandations. Une étude sur les utilisateurs a montré que les dimensions de critique suggérées par le système augmentaient l'efficacité de l'utilisateur et la variété des recommandations, tandis que la critique en général conduisait à un plus grand engagement de la part de l'utilisateur. En outre, les auteurs ont observé plusieurs effets des caractéristiques personnelles, par exemple, les participants ayant une grande connaissance du domaine et un besoin de contrôle étaient plus enclins à fournir un retour d'information. Dans une autre expérience, Jin et al [44] ont étudié les principales qualités des SRC, en tenant compte des caractéristiques importantes des conversations. Ils ont constaté que l'adaptabilité d'un chatbot et le fait qu'il comprenne l'utilisateur ont une incidence positive sur la confiance perçue et l'intention d'utiliser à nouveau le système. Cet effet étant médiatisé par le contrôle de l'utilisateur, les auteurs l'attribuent au fait que l'interaction avec un SIR est plus naturelle et plus souple qu'avec un SIR traditionnel. Alkan et al [3] montrent que tout SR non interactif peut être transformé en SIR. Deux études d'utilisateurs en ligne ont confirmé que les utilisateurs préféraient les options supplémentaires de retour d'information qu'ils étaient ainsi en mesure de fournir par rapport aux évaluations et aux mentions "j'aime" traditionnelles. Néanmoins, il convient de garder à l'esprit que les utilisateurs ne souhaitent pas nécessairement interagir avec un chatbot, par exemple en raison d'une réticence générale à s'engager avec des agents virtuels [84].
2.4 Explication des recommandations
Les SR conventionnels souffrent du problème de la boîte noire, car ils ne fournissent pas aux utilisateurs les informations nécessaires pour comprendre et évaluer le processus de recommandation, les données sous-jacentes et les résultats. L'explication des recommandations est donc de plus en plus considérée comme un moyen important de rendre les SR plus transparents et plus intelligibles pour les utilisateurs. Dans cette section, nous nous concentrerons sur certains aspects des explications centrés sur l'utilisateur. Pour un traitement plus complet du sujet, nous renvoyons au chapitre 6 (Explications et contrôle de l'utilisateur dans les systèmes de recommandation) du présent ouvrage ainsi qu'à des études récentes (Nunes et Jannach [63] et Zhang et Chen [93]).
Fournir des explications sur les articles recommandés peut servir différents objectifs [81]. Par exemple, les explications permettent aux utilisateurs de comprendre la pertinence des recommandations ou la raison pour laquelle un article a été recommandé, et elles peuvent les aider à prendre des décisions. La fourniture d'explications peut également renforcer la perception de transparence des utilisateurs et leur confiance dans le SR [69]. Par ailleurs, il a été constaté que la personnalisation des explications avait un effet positif sur leur efficacité.
Les méthodes de génération d'explications peuvent être classées en fonction du modèle de recommandation utilisé, des informations fournies et du style de présentation [93]. Parmi les approches d'explication les plus populaires, on trouve les méthodes basées sur le filtrage collaboratif, par exemple des explications du type "basé sur les évaluations de ce film par vos voisins" [29], ainsi que les méthodes basées sur le contenu qui permettent des explications basées sur les caractéristiques, montrant aux utilisateurs dans quelle mesure certaines caractéristiques de l'article correspondent à leurs préférences [86]. Les explications créées dans le cadre de l'approche du filtrage collaboratif sont principalement basées sur les évaluations ou les commentaires implicites d'utilisateurs similaires. Avec les progrès rapides des techniques de traitement du langage naturel au cours des dernières années, le retour d'information textuel, et en particulier les commentaires des clients, ont également été exploités pour expliquer les recommandations basées sur les évaluations des produits par d'autres utilisateurs. Les méthodes basées sur les avis permettent de fournir :
- les résumés verbaux des critiques, en utilisant un résumé abstrait par le biais de la génération de langage naturel [89],
- une sélection d'avis utiles (ou d'extraits) susceptibles d'être pertinents pour l'utilisateur, détectés à l'aide de techniques d'apprentissage profond et de mécanismes d'attention [15], et
- un compte rendu des avantages et des inconvénients des caractéristiques des articles, généralement à l'aide d'une modélisation des sujets ou d'une analyse des sentiments basée sur les aspects [94]. Ces informations peuvent également être intégrées dans des algorithmes de filtrage collaboratif tels que la factorisation de la matrice pour générer à la fois des recommandations et des explications basées sur les aspects.
Le format de présentation des explications joue également un rôle important dans la promotion de l'utilité des explications. Les explications peuvent être fournies sous différentes formes de texte (par exemple, texte standard, basé sur un modèle, langage structuré), de visualisations ou d'autres formats médiatiques [63]. Kouki et al [52] ont proposé une série d'explications dans une RS musicale hybride et ont testé, entre autres, l'influence du format de présentation sur la perception des utilisateurs. Dans cette étude, les auteurs ont constaté que les explications textuelles étaient perçues comme plus convaincantes que les explications fournies à l'aide d'un format visuel. Toutefois, les utilisateurs ayant une plus grande familiarité visuelle ont perçu l'une des explications visuelles de manière plus positive (un diagramme de Venn). Hernandez-Bocanegra et Ziegler [30] ont comparé des diagrammes à barres, des tableaux et des textes fournissant des informations statistiques sur les aspects évalués positivement et négativement dans les critiques d'hôtels. Ils ont également manipulé le niveau d'interactivité, c'est-à-dire la possibilité pour les utilisateurs de cliquer sur des liens les menant à des explications plus détaillées et au texte original de l'avis, s'ils le souhaitaient. Alors qu'aucun effet principal du style de présentation n'a été constaté, l'interactivité a augmenté de manière significative la qualité perçue des explications, l'efficacité des recommandations et la confiance. Il a également été constaté que les caractéristiques psychologiques des utilisateurs influençaient la perception des explications. Les décideurs plus rationnels ainsi que les participants plus sensibles aux questions sociales ont attribué aux explications une note plus élevée dans plusieurs domaines. Cette influence des caractéristiques psychologiques a également été constatée dans d'autres études.
Ces résultats indiquent que les utilisateurs peuvent préférer un niveau élevé de contrôle interactif non seulement sur le processus de recommandation, mais aussi sur les explications. À cet égard, les approches de recommandation conversationnelle (voir la section 2.3.3) offrent des possibilités intéressantes, où les utilisateurs peuvent exprimer plus librement leurs préférences, mais aussi demander des informations au système en fonction de leurs besoins actuels en matière d'explications. Un nombre limité de développements ont commencé à fournir des informations explicatives dans un style conversationnel, soit intégrées dans le flux de dialogue d'un SIR [67], soit sous la forme d'un explicateur conversationnel distinct basé sur des informations extraites des commentaires des clients [31]. Dans cette étude, les questions posées par les utilisateurs sur les recommandations d'hôtels générées par le système ont été collectées, ce qui a permis d'obtenir un ensemble de données composé de 1806 questions. Il a été constaté que les questions pouvaient être classées en deux catégories principales : les intentions liées au domaine (concernant les hôtels et leurs caractéristiques) et les intentions liées au système (concernant l'algorithme ou les données d'entrée du système). Il est intéressant de noter que seules 24 questions sur 1 806 ont pu être classées dans la catégorie des questions liées au système [32]. Cela indique que les utilisateurs sont beaucoup plus intéressés par une compréhension plus approfondie des articles recommandés et de leurs caractéristiques que par des informations sur le processus de recommandation ou sur les données d'entrée du processus.
Afin d'explorer plus avant les besoins d'explication de la classe dominante, les questions relatives au domaine ont été classées en fonction des dimensions suivantes :
- Portée : La question porte-t-elle sur un seul élément, plusieurs éléments ou est-elle indéfinie (ne faisant pas référence à des éléments spécifiques) ?
- Comparaison : Les utilisateurs demandent-ils des informations comparatives sur deux ou plusieurs éléments ?
- Évaluation : La question porte-t-elle sur des faits concernant un élément ou sur les évaluations subjectives des utilisateurs ? En outre, les questions portant sur les raisons pour lesquelles le système a recommandé un élément ont été incluses dans cette catégorie.
- Détail : La question porte-t-elle sur des caractéristiques ou des aspects spécifiques d'un article, ou sur un article dans son intégralité ?
Les résultats de la classification ont montré que la majorité des questions portaient sur des faits concernant un hôtel (par exemple, "l'hôtel X a-t-il une piscine ?"), suivies par des questions d'évaluation subjective (par exemple, "comment est la nourriture à l'hôtel X ?"). Dans l'ensemble, ces résultats indiquent que les utilisateurs souhaitent obtenir des informations qui les aident à se forger leur propre opinion sur les éléments recommandés, plutôt que de comprendre le fonctionnement interne de l'algorithme. Cela suggère également que la mise à disposition de moyens permettant d'explorer interactivement les recommandations sous différentes perspectives pourrait être utile pour satisfaire les besoins d'explication des utilisateurs, un aspect qui mérite plus d'attention dans les recherches futures.
2.5 Évaluation des systèmes de recommandation
Les méthodes d'évaluation conventionnelles pour les SR se concentrent sur l'évaluation de la précision des recommandations, qui est souvent considérée comme une approche de mesure objective. La tâche de recommandation consiste soit à prédire les évaluations manquantes, soit à apprendre un classement des éléments qui est censé refléter leur pertinence pour l'utilisateur. Des mesures telles que l'erreur absolue moyenne (MAE) et l'erreur quadratique moyenne (RMSE) mesurent la différence entre les évaluations prédites par le système et celles effectivement fournies par les utilisateurs pour les éléments. Pour les méthodes basées sur le classement, des mesures telles que la précision moyenne (MAP) et le gain cumulatif actualisé normalisé (NDCG) sont généralement utilisées. Ces mesures s'appliquent à des listes entières de recommandations et prennent également en compte les effets de position. Pour une vue d'ensemble des mesures, nous nous référons à celle fournie par Gunawardana, Shani et Yogev [26].
Du point de vue de l'utilisateur, cependant, les techniques axées sur la précision sont limitées par plusieurs lacunes. Tout d'abord, ces évaluations sont le plus souvent réalisées dans le cadre d'expériences hors ligne, qui sont rétrospectives parce qu'elles sont basées sur les commentaires des utilisateurs déjà recueillis dans le passé et représentés dans des ensembles de données statiques. Par conséquent, elles peuvent ne pas refléter l'évaluation attendue par l'utilisateur des articles dans le contexte d'utilisation actuel, qui peut créer des besoins spécifiques ou transitoires différents des préférences à long terme de l'utilisateur. Deuxièmement, la satisfaction de l'utilisateur à l'égard des recommandations ne dépend pas seulement de la précision, telle qu'elle est mesurée par les méthodes susmentionnées, mais aussi d'un certain nombre d'autres facteurs subjectifs qui influencent l'expérience de l'utilisateur avec le système [49], [50]. En conséquence, les tests A/B en ligne et les études sur les utilisateurs ont fait l'objet d'une attention croissante ces dernières années, ce qui permet d'appréhender le comportement des utilisateurs et leur évaluation des recommandations et de l'ensemble du système d'une manière plus opportune et plus complète. Une limitation difficile à surmonter dans les études expérimentales est que la consommation ou l'utilisation réelle des recommandations est rarement possible, même s'il a été démontré qu'elle affecte fortement l'évaluation des recommandations. Dans deux études sur les utilisateurs, Loepp et al [57] ont comparé la perception subjective des recommandations avant et après que les participants aient écouté les chansons recommandées ou regardé les films recommandés. Les résultats suggèrent que les utilisateurs peuvent avoir des difficultés à évaluer la valeur des recommandations raisonnablement bien avant d'en avoir fait l'expérience. Par exemple, avant de consommer les articles, ils sous-estimaient les chansons et étaient moins satisfaits de leurs choix, qu'ils avaient faits à partir d'une liste ne contenant que des informations descriptives. Cet effet était moins visible dans le domaine du cinéma, où des informations supplémentaires, telles que des photos d'affiches de films, étaient présentées. Pour les études expérimentales, cela signifie qu'il est important de présenter suffisamment d'informations sur les articles, afin de permettre aux participants de donner des notes qui se rapprochent de leur évaluation après avoir fait l'expérience des articles.
2.5.1 Facteurs de qualité centrés sur l'utilisateur
Au-delà de la précision hors ligne, un grand nombre d'autres facteurs ont été considérés comme au moins aussi importants pour évaluer un SR dans une perspective centrée sur l'utilisateur [26], [47], [50]. Parmi les facteurs les plus fréquemment examinés, on peut citer les suivants :
- Nouveauté : l'un des objectifs inhérents au SR est de suggérer des éléments que les utilisateurs ne connaissent pas. Dans les expériences avec les utilisateurs, il est facile de mesurer cet aspect en interrogeant les participants sur la nouveauté perçue des éléments recommandés, mais cela est également possible dans les expériences hors ligne, par exemple en utilisant des mesures de précision qui récompensent les systèmes différemment selon qu'ils recommandent ou non des éléments populaires [26].
- Sérendipité : Une recommandation fortuite, en revanche, fait référence à un élément qui est non seulement nouveau, mais aussi agréablement surprenant car l'utilisateur ne l'a pas cherché activement [47]. Sans sérendipité, les utilisateurs risquent d'être piégés dans une bulle de filtre [66], c'est-à-dire que les recommandations se limitent à des éléments similaires à ceux que l'utilisateur a évalués positivement dans le passé, ce qui est souvent le cas dans les approches basées sur le contenu. Cependant, il n'existe pas de véritable consensus sur la définition de la sérendipité, ce qui la rend difficile à mesurer de manière normalisée [47].
- Diversité : La diversité des éléments d'un ensemble de recommandations est une autre qualité importante des recommandations. Des études ont montré qu'une grande diversité peut accroître la satisfaction de l'utilisateur et faciliter le choix de l'un des éléments recommandés [10]. Contrairement à d'autres mesures, cette diversité peut être mesurée de manière satisfaisante même dans le cadre d'expériences hors ligne, notamment en calculant la similarité élément-élément sur la base des métadonnées de l'élément ou des facteurs latents dérivés des données de filtrage collaboratif [47].
- Fiabilité : La confiance dans les recommandations est un facteur de réussite important pour les SR. Toutefois, la confiance ne dépend pas seulement de la qualité des recommandations, mais aussi de l'expérience acquise avec l'ensemble du système dans lequel elles sont intégrées et de la fiabilité de son fournisseur. Accroître la confiance dans les recommandations elles-mêmes peut être une raison d'inclure dans la liste des recommandations des éléments qui ne sont pas nouveaux, car ils peuvent servir de point d'ancrage pour déterminer si un système produit ou non des résultats significatifs [26]. La fourniture d'explications efficaces pour les recommandations données (voir la section 2.4) peut également renforcer la confiance des utilisateurs. La confiance peut être mesurée en interrogeant les participants à une étude sur les utilisateurs ou en considérant comme dignes de confiance les recommandations acceptées par les utilisateurs dans le cadre d'études en ligne. Toutefois, il est difficile d'obtenir des informations à partir d'expériences hors ligne, car la confiance dépend de l'interaction et de l'expérience de l'utilisateur avec le système.
Divers autres facteurs peuvent également influencer l'expérience de l'utilisateur avec un SR. La facilité d'utilisation du système ou son attrait esthétique ont généralement un impact sur la perception de l'utilisateur, pour laquelle des questionnaires d'expérience utilisateur tels que UEQ-S [78] peuvent être appliqués. Pour les techniques de recommandation interactives, l'évaluation de la qualité de l'interface et de l'interaction sont des facteurs très importants. Les facteurs de contrôlabilité et de transparence sont particulièrement importants pour les techniques interactives [28]. Seuls quelques travaux ont encore abordé les critères relatifs à la classe de plus en plus importante des recommandeurs conversationnels basés sur des dialogues en langage naturel. La compréhension des expressions écrites ou orales des utilisateurs et la qualité des réponses du système sont les principaux aspects de la qualité de ces systèmes, mais les facteurs liés au processus de communication peuvent revêtir une importance similaire. Jin et al [44] proposent plusieurs facteurs particulièrement pertinents pour les recommandeurs utilisant des interfaces utilisateur conversationnelles (CUI), notamment la positivité, l'attention et la coordination, qui peuvent être résumés sous le concept de rapport. La positivité fait référence à l'amabilité et à l'attention mutuelle des partenaires de la communication, tandis que l'attention décrit une interaction ciblée et cohésive, et la coordination une communication synchrone et harmonieuse.
2.5.2 Cadres d'évaluation et questionnaires
Pour évaluer la qualité des RS de manière plus fiable et plus normalisée, plusieurs cadres d'évaluation ont été proposés, qui fournissent un ensemble d'éléments de questionnaire statistiquement éprouvés, organisés en fonction d'un certain nombre de facteurs de qualité. Ces cadres constituent un moyen important de comparer les systèmes à des lignes de base et à d'autres options de conception. Les cadres dimensionnels organisent les questions du questionnaire autour d'un ensemble de dimensions de haut niveau, chacune d'entre elles étant décomposée hiérarchiquement en un ensemble de concepts mesurés par des éléments concrets, souvent à l'aide d'échelles de Likert. Un exemple bien connu de ce type est ResQue [70], qui est organisé selon les dimensions suivantes : qualités perçues du système, croyances des utilisateurs résultant de ces qualités, leurs attitudes subjectives et leurs intentions comportementales. La dimension des qualités perçues du système, par exemple, est décomposée en plusieurs éléments : qualité de la recommandation (comprenant des éléments tels que la précision, la nouveauté, l'attrait et la diversité perçus), adéquation de l'interface (couvrant les informations fournies et les aspects de présentation), adéquation de l'interaction (liée à l'élicitation et à la modification des préférences) et suffisance et explicabilité de l'information. D'autres facteurs subordonnés comprennent, entre autres, l'utilité et la facilité d'utilisation perçues, le contrôle et la transparence, la satisfaction et la confiance globales, ainsi que des éléments liés aux intentions d'utilisation et d'achat.
Dans ResQue, on suppose déjà qu'il existe des relations d'influence entre les éléments du cadre. Cette notion est étendue par le cadre proposé par Knijnenburg, Willemsen et Kobsa [48], Knijnenburg et Willemsen [49], qui est basé sur un modèle structurel représentant des relations qui peuvent être interprétées de manière causale. Le modèle propose une chaîne de relations allant des propriétés objectives du système aux aspects du système perçus subjectivement, qui à leur tour influencent l'expérience et l'interaction de l'utilisateur. Le cadre a été validé dans un certain nombre d'études d'utilisateurs, qui ont confirmé que les aspects objectifs du système, tels que la recommandation ou la méthode d'obtention des préférences, influencent l'évaluation des aspects subjectifs du système, y compris la facilité d'utilisation générale et, en particulier, des dimensions telles que la qualité et la diversité perçues des recommandations. L'évaluation de ces aspects influe à son tour sur l'expérience de l'utilisateur, notamment en ce qui concerne l'efficacité perçue du système, l'effort perçu au cours du processus de recommandation et la satisfaction de l'utilisateur à l'égard des éléments finalement choisis. Enfin, l'expérience utilisateur est fortement liée au comportement d'interaction de l'utilisateur, tandis que toutes ces dimensions sont modérées par des caractéristiques personnelles et situationnelles. Ce modèle structurel de haut niveau peut être alimenté par différents concepts et éléments concrets en fonction de l'objectif de l'étude. L'un des principaux avantages de ce modèle est qu'il peut être testé statistiquement à l'aide d'une modélisation par équations structurelles, ce qui permet d'obtenir des informations plus approfondies que les simples questionnaires d'évaluation à un seul niveau.
2.5.3 Méthodes d'évaluation
Les évaluations liées à la précision utilisent généralement des données de retour d'information utilisateur-article qui ont été collectées à partir du SR cible utilisé, ou des ensembles de données existants. Si de telles données sont disponibles, une méthode de recommandation nouvelle ou optimisée peut être étudiée de manière relativement simple et peu coûteuse par le biais d'expériences hors ligne [26], ce qui peut être particulièrement utile pour choisir un algorithme de recommandation approprié. Toutefois, l'évaluation centrée sur l'utilisateur nécessite la participation d'êtres humains à la procédure d'évaluation.
Dans l'industrie, les tests A/B sont une approche populaire pour évaluer l'efficacité des différentes variantes d'un système en production. Les tests A/B permettent d'analyser les effets qu'une modification peut avoir sur le comportement des utilisateurs et, dans une certaine mesure, sur leur satisfaction réelle, par exemple lorsque les taux de clics ou les achats augmentent. Pour réaliser un test A/B, un ou plusieurs groupes d'utilisateurs sélectionnés au hasard se voient présenter le système modifié, généralement sans savoir qu'ils se trouvent dans une condition expérimentale. Le système modifié peut mettre en œuvre une nouvelle méthode de recommandation, présenter les recommandations différemment ou fournir un nouveau mécanisme d'interaction. Les données d'enregistrement sont ensuite comparées au groupe de contrôle, c'est-à-dire aux utilisateurs qui voient la variante originale du système. Les grandes entreprises sont connues pour effectuer plusieurs centaines de tests A/B simultanément sur leurs plateformes. Les tests A/B sont une approche exploratoire basée sur des données d'interaction objectives qui peuvent fournir des informations importantes, en particulier lorsqu'un grand nombre d'utilisateurs est impliqué. Son pouvoir explicatif est toutefois limité car les évaluations subjectives des utilisateurs ne sont pas prises en compte. D'autres défis se posent, par exemple, une infrastructure technique spécifique est nécessaire, ce qui est bien illustré par Xu et al [91] pour l'exemple de LinkedIn.
La réalisation d'études sur les utilisateurs (en laboratoire ou en ligne) permet d'effectuer des analyses plus approfondies des perceptions et des jugements des utilisateurs à l'égard du système, ce qui peut élucider les raisons de leur comportement d'interaction et fournir des informations plus généralisables que celles que l'on peut obtenir à partir des données d'enregistrement. Les études de laboratoire sont généralement réalisées avec un nombre réduit de participants, mais elles peuvent fournir un retour d'information plus complet en appliquant des techniques de réflexion à haute voix ou des données perceptuelles capturées par suivi oculaire. Des nombres beaucoup plus importants de participants, généralement plusieurs centaines, sont nécessaires pour des analyses avancées telles que la modélisation par équations structurelles, par exemple en utilisant le cadre de Knijnenburg, Willemsen et Kobsa [48]. Les expériences en ligne financées par la foule sont donc souvent réalisées pour recruter un nombre suffisamment important de participants. Elles permettent également de réaliser des études en peu de temps, puisque les participants peuvent travailler en parallèle. Cependant, elles présentent également des limites, car il est plus difficile de contrôler la composition et le contexte de l'échantillon, ainsi que l'utilisation du système. En outre, la formulation des tâches à effectuer doit faire l'objet d'une attention particulière. Pour une discussion sur les avantages et les inconvénients du crowdsourcing, nous nous référons à l'aperçu fourni par Archambault, Purchase et Hoßfeld [6].
Une autre approche intéressante de l'évaluation des RS réside dans les études de simulation, qui n'ont toutefois commencé à attirer l'attention de la recherche sur les RS que récemment [60]. Dans ce cas, l'exposition des utilisateurs aux recommandations et leur comportement de choix correspondant sont simulés. Cette méthode est moins coûteuse que les études avec des utilisateurs réels, elle permet de tester différentes configurations de SR et peut aider à étudier les effets à long terme.
2.6 Résumé et orientations futures
La recherche et l'industrie sont de plus en plus conscientes de la nécessité de concevoir et d'évaluer les SR dans une perspective centrée sur l'utilisateur. Au-delà des performances algorithmiques, les perceptions et les attitudes des utilisateurs à l'égard des SR sont d'une importance cruciale pour le succès des SR. La transparence et le contrôle se sont révélés être des desiderata importants pour la conception de systèmes centrés sur l'utilisateur. Bien que de nombreux travaux aient proposé des méthodes pour atteindre ces objectifs, la stratégie optimale n'est pas encore en vue et ne le sera peut-être jamais.
La conception centrée sur l'utilisateur, en général, nécessite une compréhension approfondie des objectifs des utilisateurs, de leurs capacités et de leurs limites, ainsi que du contexte d'utilisation, ce qui est également vrai pour le développement de RS centrés sur l'utilisateur. La recherche dans cette perspective reste cependant beaucoup plus limitée que les travaux liés aux algorithmes. L'une des nombreuses questions ouvertes en matière d'IHM est la conception des RS dans leur contexte d'application. Les SR ne sont pas utilisés de manière isolée, mais font généralement partie d'un système plus vaste, tel qu'une boutique en ligne. Dans ce contexte, il convient de mieux comprendre l'interaction entre les différentes formes d'interaction, telles que la navigation, la recherche et l'exploration de recommandations. Pour aider les utilisateurs qui doivent accomplir des tâches plus complexes que le choix d'un film ou d'une chanson, il conviendrait d'intégrer davantage de connaissances du domaine dans les SR, afin de faciliter la recherche et d'expliquer les éléments candidats. De nouvelles formes de recommandation, telles que les approches conversationnelles, promettent d'offrir des moyens plus interactifs et plus souples d'exprimer ses besoins et ses préférences. Les progrès récents dans le domaine des grands modèles de langage promettent d'intéressantes possibilités futures, tout en soulevant une multitude de questions ouvertes, notamment l'acceptation et la fiabilité de systèmes dotés de capacités apparemment humaines.
Enfin, de nombreuses questions restent en suspens quant à ce qui constitue une bonne recommandation. Un large éventail de méthodes, de mesures et de techniques d'évaluation a été proposé, mais la question de savoir comment aider réellement les utilisateurs à prendre de meilleures décisions n'a pas encore trouvé de réponse définitive.
